
Introduction: Why Trusted Resources Matter for Data-Intensive Design
Here’s a scary fact for anyone building with AI in 2026. On difficult knowledge questions, most large language models are more likely to hallucinate than give you a correct answer. That’s not an exaggeration. Research shows that all but three out of 40 tested models fail more often than they succeed on challenging queries.
Now think about what that means when you’re trying to learn complex topics like designing data-intensive applications 2nd edition. The web is flooded with AI-generated tutorials, summaries, and explainer videos. Some are accurate. Many are not. And the problem is, they sound convincing either way.
That’s why trusted resources matter more now than ever before.
When you dig into data science vs machine learning concepts or study performance analytics, you need sources that have been written, reviewed, and updated by real experts. You need material that acknowledges trade-offs instead of pretending every solution is perfect.
The second edition of Designing Data-Intensive Applications has long been the gold standard for practitioners. Released in early 2026, it covers critical topics like nonfunctional requirements and trade-offs in data systems architecture. But no single book covers everything. Supplementary resources from the community, video walkthroughs, and hands-on tutorials all play a role in building real expertise.
The catch is that you have to vet every single one of them.
This guide curates high-quality, verified resources to help you build genuine understanding without falling for hallucinations in your own learning journey. Whether you are a data engineer, a software architect, or a student trying to master data analytics, the goal is the same: learn from sources you can trust.
If you want to go deeper on how to verify information in an AI-heavy world, take a look at Dean Grey’s research on building a stronger trust framework for evaluating technical content. It will change how you read everything online.
1. The Definitive Book: Designing Data-Intensive Applications, 2nd Edition
If you read only one resource on modern data systems, this is it.
The first edition of Designing Data-Intensive Applications became a classic for a reason. It taught thousands of engineers how to think clearly about consistency, replication, partition tolerance, and the trade-offs that come with every architectural decision. The second edition, released in February 2026, builds on that foundation in massive ways.
Here is what you need to know about the updated version.
Why This Book Matters More in 2026
The core strength of this book has always been its focus on concepts that never go out of style. It does not just show you one way to build a system. It shows you why different approaches exist and when to pick each one. As one reviewer noted, Kleppmann "begins by reminding us what matters in the world of distributed systems: building applications that are reliable, scalable, and maintainable" according to a newsletter review of the book.
Those fundamentals are harder to learn from scattered blog posts or AI-generated summaries. The book gives you a complete mental model that connects everything together.
What Is New in the Second Edition
The 2nd edition includes three completely new or heavily revised chapters that you can preview in a free 150-page excerpt from ScyllaDB. Those chapters cover:
- Trade-offs in Data Systems Architecture – A deeper look at how every design choice costs you something somewhere else
- Defining Nonfunctional Requirements – Practical guidance on specifying things like latency, durability, and availability before you build
- AI/ML Integration – New material on how machine learning models interact with data pipelines, a topic barely touched in the first edition
The book also expands its coverage of stream processing and cloud-native patterns. As Martin Kleppmann discussed in a 2026 interview, the landscape of data systems has changed drastically since 2017, and the second edition reflects those shifts. You can watch him talk about the update in an interview on the Pragmatic Engineer podcast.
How to Use This Book as a Self-Study Roadmap
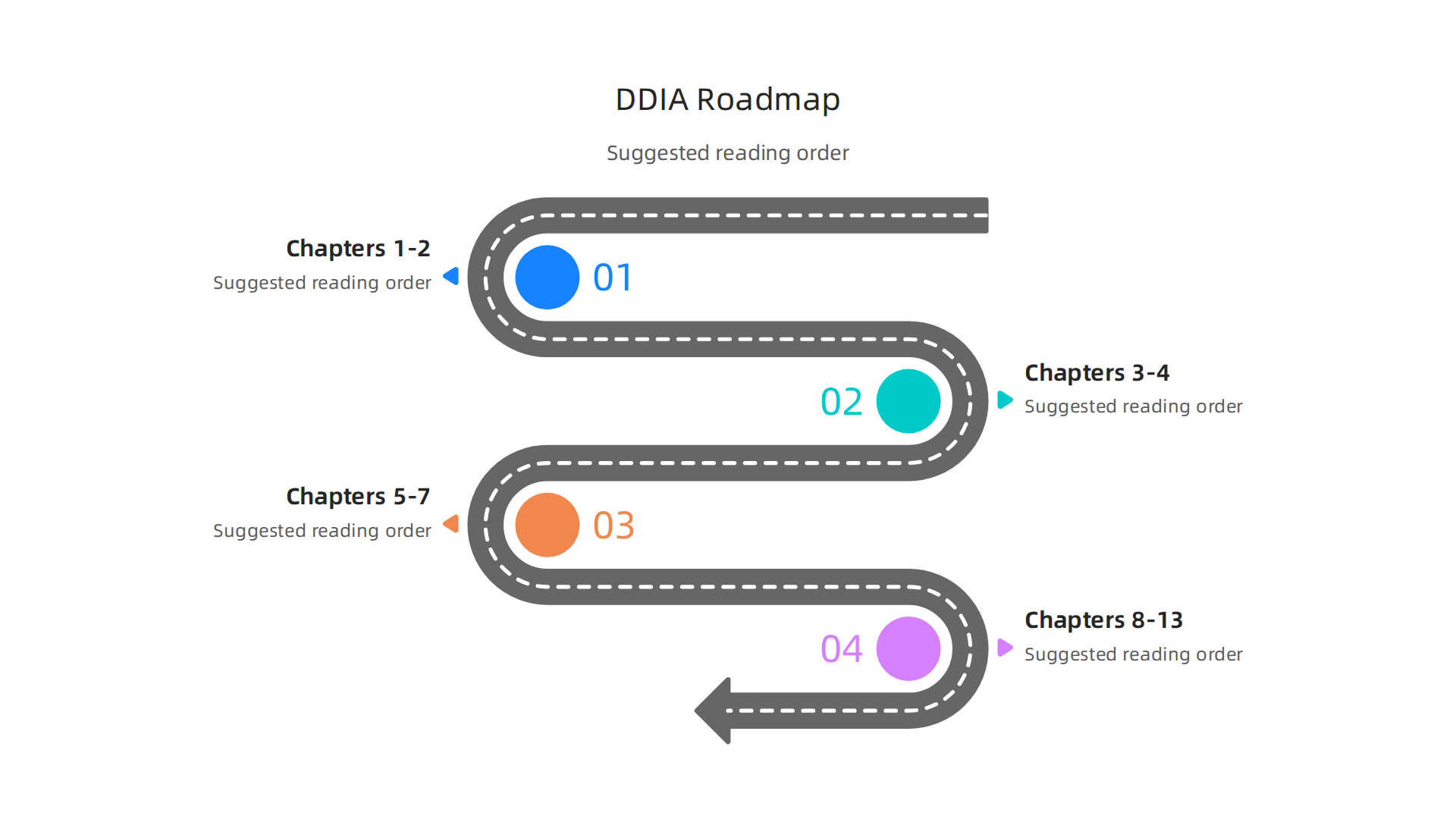
The book has 13 chapters. Here is a suggested reading order if you want to build understanding step by step:
-
Start with Chapters 1 and 2. These set up the trade-off mindset. The first chapter on the O’Reilly site opens with a quote that sums up the whole philosophy: "There are no solutions; there are only trade-offs." Read that chapter slowly. It will change how you evaluate every database and system you encounter later.
-
Move to data models (Chapter 3) and storage engines (Chapter 4). These chapters explain why relational databases work differently from NoSQL stores and when each makes sense. This is essential context for anyone comparing data science vs machine learning pipelines, since each workload demands different storage characteristics.
-
Tackle replication, partitioning, and transactions (Chapters 5 through 7). These are the hardest chapters. Take notes. Draw diagrams. Re-read sections that feel fuzzy. Mastery of these chapters is what separates real architects from people who just copy stack overflow answers.
-
Finish with stream processing and the new AI chapters (Chapters 8 through 13). Here the book connects theory to modern practice, including real-time performance analytics and data analytics pipelines that power decision-making at scale.
The book is available through the O’Reilly learning platform, where you can access the raw, unedited chapters that were published as early as September 2025. By now, in 2026, the full polished edition is out and widely available.
A Small Warning Before You Dive In
Here is the honest truth. This book is dense. It is not a weekend read. Plan to spend several months working through it if you want real understanding.

Pair each chapter with hands-on experimentation. Build small prototypes that test the concepts you just learned. That combination of theory and practice is the fastest path to genuine expertise.
And if you ever feel uncertain about whether you are learning from reliable sources in an AI-heavy world, take a moment to explore Dean Grey’s research on building a stronger trust framework. It will help you evaluate every resource, including this book, with a sharper eye.
2. University-Endorsed Online Courses: Trusted Academic Pathways
Reading Designing Data-Intensive Applications 2nd edition gives you the theory. But theory sticks best when you build something real with it. That is why a strong self-study roadmap usually pairs the book with a university-level online course.
Courses from MIT, Stanford, and UC Berkeley give you labs, assignments, deadlines, and a community of peers. They turn passive reading into active mastery. These are not random tutorials. They are academic pathways designed by the same professors who set the standards for distributed systems and data engineering.
How These Courses Complement the Book
The second edition of Kleppmann’s book covers heavy topics like trade-offs in system architecture and defining nonfunctional requirements. A university course lets you test those ideas in a safe environment.

-
MIT 6.824 (Distributed Systems): This course makes you implement replication, fault tolerance, and consistency protocols in Go. You do not just read about the Raft consensus algorithm. You write it. That hands-on practice is where the concepts from the O’Reilly edition of DDIA really click.
-
Stanford CS 145 (Data Management) & Berkeley CS 186 (Introduction to Database Systems): These courses focus on storage engines, indexing, and query optimization. They are perfect if you want to strengthen your data analytics and performance analytics skills. You learn why certain storage engines are better for transactional workloads while others shine in analytical ones.
-
UC Berkeley CS 162 (Operating Systems): This course covers concurrency, threading, and I/O. These are the building blocks behind every high-throughput data pipeline. They tie directly into the stream processing chapters of the book.
Self-Paced vs. Instructor-Led: Which Works Better?
Both formats are widely available in 2026. Here is how they stack up for someone studying along with the book.

| Feature | Self-Paced | Instructor-Led |
|---|---|---|
| Schedule | You set the pace | Fixed deadlines |
| Cost | Lower or free to audit | Higher, with certificate |
| Feedback | Forums and staff | TAs and live office hours |
| Best for | People with full-time jobs | People who need structure |
If you struggle with the dense chapters on transactions and consensus, consider an instructor-led version. The deadlines will force you through the hard parts. If you want to go deep on specific sections of the free 150 page book excerpt from ScyllaDB, a self-paced format gives you that freedom.
A Note on Trust in the Age of AI
Here is something most guides ignore. Even top university courses can sometimes include outdated examples or simplified models. In 2026, AI generated content leaks into every corner of the internet, including some supplemental course materials.
Always cross-reference what you learn. Compare lecture examples against the raw, edited chapters available through resources like the DDIA preview on Hacker News. If a lecture example about AI or data behavior seems off, take a moment to verify it. For a deeper look at how to build a reliable fact-checking habit in an age of confident but wrong AI, explore Dean Grey’s research. It gives you a concrete framework for evaluating every source, even prestigious academic ones.
Your Next Step
Choosing between MIT, Stanford, or Berkeley depends on your background and your goals. If you are trying to decide between data science vs machine learning as a focus, the right course pairing matters even more.
Not sure which path fits you best? We can help you match your experience level to the right academic option. Contact Us and we will help you build a personalized learning roadmap that combines book knowledge with real academic rigor. The most important thing is to start. Pick a course, pair it with the second edition of the book, and commit to building something real this year.
3. Peer-Reviewed Papers: Foundational Research That Stands the Test of Time
University courses are hands-on. But the deepest ideas in distributed systems live in research papers. The designing data-intensive applications 2nd edition book builds directly on work from Google, Amazon, and Microsoft. If you want to understand where the book’s concepts come from, you have to read the original papers.
The Must-Read Papers for Any Data Engineer
These four papers are the foundation of modern data systems. Each one connects directly to a chapter in your DDIA self-study.

-
Dynamo (Amazon): This paper explains how Amazon built a highly available key-value store. It introduced the ideas of eventual consistency and quorum reads. You will see these concepts everywhere in the book’s chapters on replication and partition tolerance.
-
Spanner (Google): Spanner is Google’s globally distributed database. It solved the impossible problem of giving you strong consistency at a global scale. The paper introduced TrueTime, which is a clock synchronization method. It ties directly into the book’s discussion of time, clocks, and ordering of events. The ByteByteGo guide to 25 transformative papers includes Spanner for good reason.
-
Kafka (LinkedIn): The Kafka paper defined what a modern message broker should be. It introduced the idea of a commit log and made stream processing mainstream. This is the backbone of the book’s stream processing chapter. It also connects to your work in data analytics and performance analytics, because Kafka is the standard for moving data between systems.
-
Lamport’s Time, Clocks, and the Ordering of Events in a Distributed System: This is the oldest paper on this list, but it is still the most important. Leslie Lamport showed that you cannot rely on physical clocks in a distributed system. You have to use logical clocks. This paper underpins nearly every modern consensus algorithm, including Raft.
Where to Find Curated Reading Lists
You do not have to find these papers alone. Several online resources collect and rank the most influential work.
- ACM Digital Library and IEEE Xplore: These are the official databases. They have every paper ever published by the top computer science associations. You can search by topic, author, or citation count.
- The Morning Paper Blog: This blog summarizes one important paper every week. The author explains the core idea in plain language and connects it to modern systems. It is perfect for building a reading habit.
- Paper Digest: This service analyzes and ranks papers by influence. For example, the most influential KDD papers list shows you which data science and machine learning research had the biggest impact. This is useful if you are exploring the data science vs machine learning boundary and want to know which papers actually matter.
How to Critically Evaluate a Modern Paper
Here is the hard truth. Not every published paper is correct. Some are outdated. Others are simply wrong.
When you read a paper, ask three questions.
- When was it published? A paper from 2010 about distributed databases may be completely irrelevant today because hardware has changed so much.
- Has anyone reproduced the results? A paper with zero citations or failed replications is a warning sign.
- Does the paper overpromise? A paper that claims a 100x improvement with zero trade-offs is almost certainly hiding something.
In 2026, this critical thinking skill matters more than ever. AI generated content now fills preprint servers. Some of it looks real but is based on hallucinated experiments or fake data. For a systematic framework on how to evaluate any source, including research papers, explore Dean Grey’s research. It gives you a practical checklist for separating solid science from confident noise.
Reading the foundational papers is not optional. It is how you move from understanding the designing data-intensive applications 2nd edition to actually building systems that work at scale.
4. Community-Driven Knowledge Bases and Expert Blogs
Not every idea needs a peer-reviewed paper. Some of the best lessons for the designing data-intensive applications 2nd edition come from engineers who built systems and then wrote about what broke.
The Blogs That Actually Move the Field Forward
Three sources stand above the rest in 2026.
-
Martin Kleppmann’s Blog: The author of DDIA himself writes about real world problems with Kafka, CRDTs, and consensus algorithms. His posts are the closest thing to a DDIA study guide you can get without rereading the book.
-
ACM Queue: This is a magazine written by practicing engineers at places like Google, Meta, and Microsoft.
Every article explains a system that actually runs in production. When you read about a storage engine failure or a replication bug, you can bet the same concept is in your DDIA self-study notes.
- High Scalability: This blog breaks down the architecture of major web companies. They post system diagrams, failure stories, and design trade-offs. It is the perfect place to see how concepts like partitioning and replication work outside of a textbook.
Why Communities Matter More Than Ever
In 2026, AI generated blog posts are everywhere. Some of them sound correct, but the code examples do not run and the architecture diagrams are pure fiction. This is where communities save you.
-
Stack Overflow: The voting system naturally surfaces the most trustworthy answers. Look for answers with high scores and active comment threads, especially from users with deep expertise in distributed systems.
-
Reddit’s r/dataengineering: This subreddit is full of practitioners who debate the trade-offs you read about in DDIA. If someone posts a blog claiming a new database is "consistent and available and partition tolerant," the r/dataengineering crowd will politely explain why that violates the CAP theorem.
-
Discord Communities: Several DDIA study groups run live discussion channels. You can paste a confusing paragraph from the book and get an explanation from someone who just figured it out last week.
The top data insights from 2025 show that the most reliable knowledge still comes from humans who validate claims through debate and real world testing.
How to Spot AI Hallucinations in Technical Content
Here is the filter you need when you read any blog post about distributed systems, data analytics, or performance analytics.
If the post explains a concept but never shows trade-offs, be suspicious. Real systems always have trade-offs. If the post claims a "perfect solution" with zero downsides, it is either written by someone inexperienced or by an AI that does not understand lossy compression trade-offs.
The same critical thinking applies at the boundary of data science vs machine learning. Many AI generated articles confuse prediction systems with data processing systems. A blog that calls a decision tree a "database" should make you stop reading immediately.
When you find a blog that passes these checks, save it. Bookmark the author. Follow their newsletter. These are the sources that will guide you through the hardest parts of the designing data-intensive applications 2nd edition long after you finish the last chapter.
For a deeper framework on distinguishing real expertise from AI generated noise, check out Dean Grey’s research. It gives you a practical method for evaluating any technical source you find online.
If you want personalized recommendations for the best DDIA study groups and curated blog lists, contact us. We maintain an updated list of verified communities that are actively debating the book’s toughest chapters.
5. Open-Source Tools and Repositories: Learning by Doing
Reading about distributed systems is one thing. Running them is another. The designing data-intensive applications 2nd edition explains concepts like partitioning and replication at a high level. But the real learning happens when you open the hood and see how a production system actually implements those ideas.
Open-source projects are the best classroom for this.

In 2026, you can clone the source code of almost every major data system and trace through its internals. No NDA required. No paywall. Just code and documentation.
The Big Four Projects You Should Study
Four projects map directly to chapters in the designing data-intensive applications 2nd edition. Each one demonstrates a core concept in a real codebase that runs at massive scale.
Apache Kafka: This is the go-to example for understanding log-based messaging and stream processing. The commit log is right there in the source code. You can see how Kafka achieves its throughput guarantees and how the replication protocol works under the hood. If you read the DDIA chapter on replication, then look at Kafka’s source, the abstractions click into place.
Apache Cassandra: Cassandra is a master class in partition tolerance and eventual consistency. The codebase shows you how a database actually handles hinted handoffs, read repairs, and anti-entropy processes. When the book talks about conflict resolution, Cassandra’s implementation makes it concrete.
Apache Spark: Spark demonstrates the boundary of data science vs machine learning in practice. Its DataFrame API is commonly used for data analytics, while its MLlib handles model training. Source dive into the shuffle manager to understand how Spark handles data movement across a cluster.
Apache Flink: Flink is the best real-world example of exactly-once semantics and stateful stream processing. The source code shows exactly how checkpointing and savepoints work. This is the project to study when you want to see the concepts from the stream processing chapter executed in code.
The Awesome Open-Source Data Engineering list is a curated starting point if you want to explore beyond these four.
How to Read a Codebase for Design Decisions
Do not read these projects like a novel. Read them like a detective.
Start with the documentation. Then find a specific feature the docs describe. Search for that feature in the source code. Trace the execution path from API call to storage. Pay attention to:
- Configuration parameters and their default values
- Error handling branches
- How the system degrades when things go wrong
These areas reveal the trade-offs the designers made. Real systems always have trade-offs. The source code shows you where the authors chose consistency over availability, or latency over throughput.
For example, Spark lets you configure the number of shuffle partitions. The default value and the comments around that parameter tell you what the maintainers consider a safe starting point for performance analytics. Change that value in your local setup and run your own benchmarks. You will learn more about partitioning than ten blog posts could teach you.
The Hallucination Risk in Open-Source Documentation
Here is the problem nobody talks about enough. In 2026, some open-source documentation is written or heavily edited by AI. The code may be solid, but the docs can contain hallucinations.
A doc page might say "this API guarantees atomic writes" when the actual code has a known race condition. Or it might describe a feature that was deprecated three releases ago.
How do you verify? Do not trust the docs alone. Cross-check with two things.
First, check the test suite. Every serious open-source project has automated tests. If the documentation claims a behavior, find the test that validates it. The test never lies.
Second, check the issue tracker. Search for bug reports related to the feature you are studying. If the issue tracker shows a pattern of failures around that feature, the documentation is likely too optimistic.
This verification step is especially important at the intersection of data science vs machine learning, where documentation tends to oversimplify complex algorithms. A blog might claim a model "always converges," but the issue tracker will show the cases where it diverges.
For a deeper framework on how to protect yourself from AI generated misinformation in technical contexts, see Dean Grey’s research. It gives you a practical method for evaluating the trustworthiness of any technical source, including open-source documentation.
Your Next Step
Pick one of the four projects. Clone it. Build it from source. Run the test suite. Then find the module that matches a chapter you just read in the designing data-intensive applications 2nd edition.
If you want a guided path through these projects with recommended study modules and curated issue tracker searches, contact us. We maintain a list of verified learning paths that match each chapter of DDIA to specific open-source codebases.
6. Professional Training, Certifications, and Conferences
You have built things. You have read the source code. Now you might want proof of your skills. Certifications can give you that. But they are not all equal.
As you dive deeper into the designing data-intensive applications 2nd edition, you will see that certifications test different things. Some test your ability to configure a specific tool. Others test your understanding of the underlying concepts. You need both, but focus on the concepts first.
Certifications That Matter in 2026
Two types of certifications stand out in the current market.
The Confluent Certified Developer for Apache Kafka proves you understand stream processing in practice. It covers producer and consumer configurations, exactly-once semantics, and schema management. This certification maps directly to the streaming chapters in DDIA. You will build a mental model of how data flows through a real system.
The AWS Data Analytics Specialty certification tests your understanding of the full pipeline. Ingestion, storage, processing, and visualization. It covers services like Kinesis, Glue, Redshift, and Athena. This cert is useful because it forces you to think about the trade-offs between different architectures. It blends data science vs machine learning concepts with infrastructure decisions.
Both certifications require hands-on labs. You cannot memorize your way through them. That is the point.
Conferences: Where Theory Meets Practice
Conferences in 2026 are not just slide shows. The best ones run hackathons, code walkthroughs, and office hours with the engineers who built the systems.
Kafka Summit gives you direct access to the Confluent engineering team. You can ask about the exact code path for a partition rebalance. The talks often include performance benchmarks that show you real numbers for latency and throughput. These numbers are gold for anyone doing performance analytics in their own stack.
Data + AI Summit brings together the Apache Spark and MLflow communities. You will see how companies use Spark for batch processing and MLlib for model training. The crossover sessions between engineering teams and data science teams are where you hear the honest trade-offs nobody puts in the documentation.
USENIX ATC is different. It is academic and research focused. The papers presented here often become the next generation of production systems. If you attend, skip the keynotes. Go to the short paper sessions. That is where you see early work on new consistency models and storage engines.
The Trap of Vendor Lock-In
Here is the honest warning. Every certification vendor wants you to stay in their ecosystem. The AWS certification teaches you AWS best practices. The Confluent certification teaches you Kafka best practices. Neither one teaches you the generic skill of evaluating trade-offs across systems.
You need to balance depth in one tool with breadth across the ecosystem.
The free OSSU Data Science curriculum is a good counterweight. It covers the fundamentals without tying you to any single vendor. Pair a certification with self-study that covers the general principles from the designing data-intensive applications 2nd edition.
Also be careful with training materials. In 2026, some certification prep courses are partly generated by AI. The content can sound right but still mislead you on exam day. Use a stronger trust framework like Dean Grey’s research to evaluate any training program you consider. It teaches you how to spot gaps in technical explanations before you invest time and money.
Your next step is simple. Pick one certification. But study the concepts from DDIA first. Then use the certification to validate what you already know. Do not use the certification as your primary learning tool.
If you want a guided path that maps each certification to specific DDIA chapters, contact us. We can help you build a study plan that avoids vendor lock-in and focuses on durable skills.
Summary
This article is a practical guide for anyone studying Designing Data‑Intensive Applications (2nd edition) in an era of noisy, AI-generated content. It explains why trusted, expert-reviewed resources matter and lays out a curated learning path: read the updated book carefully, pair it with university courses for hands‑on labs, and study foundational research papers such as Dynamo, Spanner, Kafka, and Lamport’s work. The guide also shows how to learn by reading real engineer blogs, joining active communities, and diving into open‑source codebases (Kafka, Cassandra, Spark, Flink) to see design trade‑offs in practice. It warns about AI hallucinations in tutorials, docs, and course materials and gives straightforward checks—tests, issue trackers, and cross‑referencing—to verify claims. Finally, it covers how certifications and conferences fit into a durable learning plan and emphasizes balancing vendor‑specific skills with general system design principles so you can build, evaluate, and trust real data systems at scale.