
You have probably seen it happen. You ask an AI a question, and it gives you an answer that sounds confident and well-written. But when you check, it is completely wrong.

This is called an AI hallucination, and it is a bigger problem than most people realize. In fact, according to a 2026 analysis titled Are AI Hallucinations Getting Better or Worse?, using AI output that contains errors can spread false information, damage reputations, and cause other serious problems.
These mistakes cost businesses a lot of money. They also chip away at trust in AI tools. So what can you do? The first line of defense is data annotation. This means carefully labeling data so the AI learns the right patterns. But data annotation alone is not enough. You also need rigorous secondary data analysis to catch the errors that slip through.
On data annotation reddit threads, people share real-world tips for catching hallucinations. These community insights are gold for anyone in data science jobs or trying to study AI safety. This guide gives you a step-by-step approach. You will learn how to combine good data annotation with careful analysis. We will use proven resources and real community advice to help you minimize the risk of AI hallucinations.
If you want to dive deeper right now, check out this complete guide on data annotation and AI hallucinations.
And remember: AI can sound right and still mislead. So Trust AI Less Blindly.
The Real Cost of AI Hallucinations
AI hallucinations are not just a tech problem. They cost real money. According to a 2026 report on the true cost of AI hallucinations in business data, each employee spends about $14,200 per year just checking and fixing AI mistakes. That adds up fast. For a team of twenty people, you are looking at nearly $300,000 a year in lost time and effort.
Different industries feel this pain differently. In healthcare, a hallucinated diagnosis could lead to wrong treatment and lawsuits. In finance, a made-up number in a report can cause bad investments and regulatory fines. Even content teams suffer when fake facts damage brand trust.

The costs go beyond money. They hit your reputation too.
Regulators are paying close attention. The MIT Sloan review of When AI Gets It Wrong shows that between 2023 and 2025, judges around the world issued hundreds of rulings about AI hallucinations in court filings. Roughly 90% of those decisions came from the United States. That means real legal risk for companies that rely on AI without proper checks.
This is why strong data annotation and careful secondary data analysis are worth the investment. When you label training data well and double-check it, you catch errors before they turn into expensive problems. People in data science jobs know this firsthand. On data annotation reddit threads, professionals share stories about how sloppy labeling led to costly mistakes. Those community insights are a goldmine for anyone who wants to study AI safety and avoid similar disasters.
Quantifying the problem is the first step to building a solid business case for better annotation. Once you see the dollar signs, it becomes much easier to push for more rigorous processes. To understand the specific techniques that can save your business thousands, check out this guide on how to catch AI hallucinations before they hurt your business.
Why AI Hallucinations Occur: Root Causes
AI hallucinations do not happen randomly. They come from clear root causes, and knowing these causes is the first step to fixing them. The three main sources are training data gaps, model architecture limits, and the temperature setting during inference.
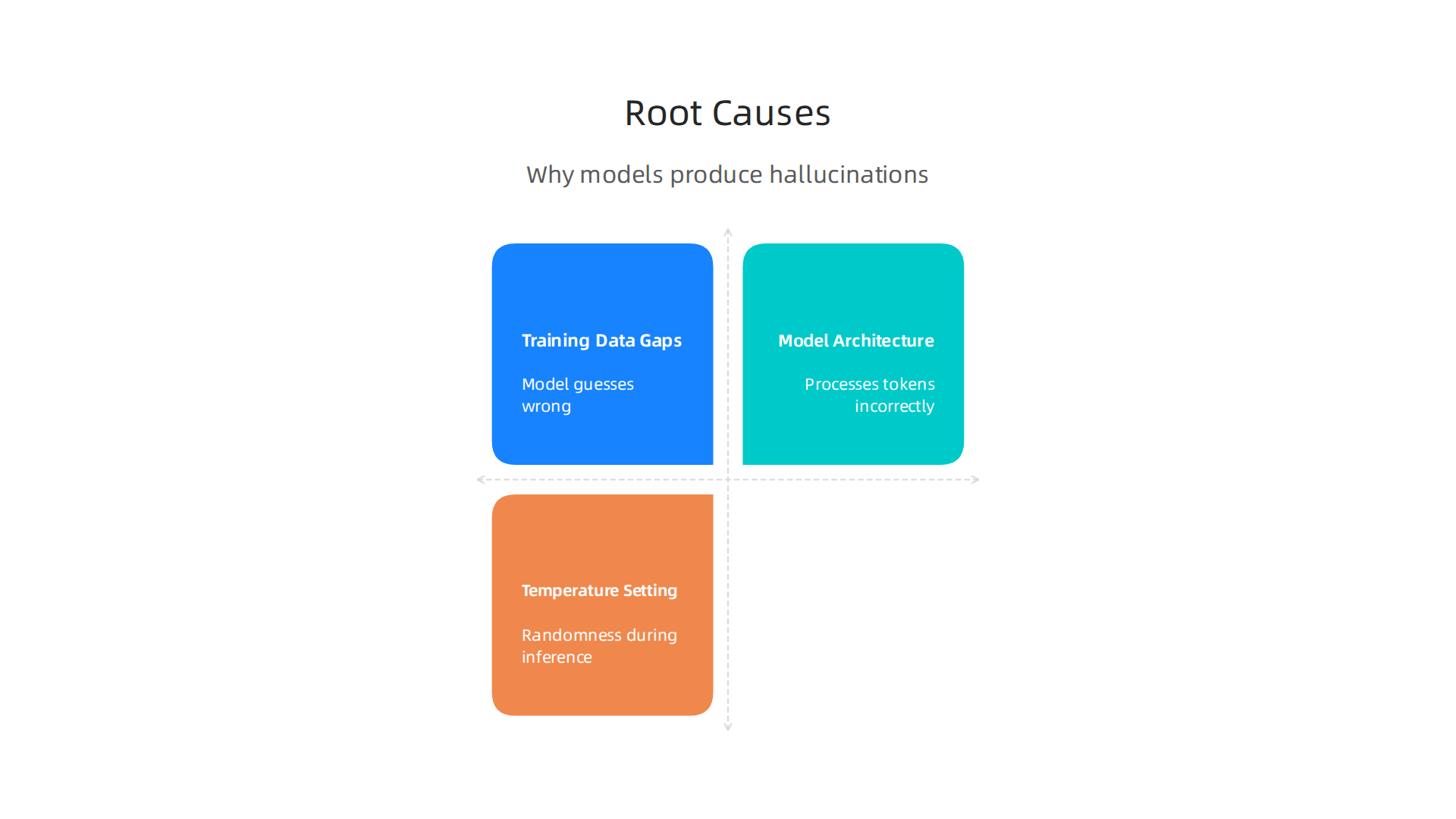
Training data gaps are the biggest culprit. If a model never saw certain facts or patterns in its training data, it will guess. And it will guess wrong. This is where data annotation becomes critical. Professionals who work in data annotation reddit threads often point out that filling those gaps with high quality labeled data dramatically reduces errors. Many AI hallucinations actually stem from data design problems behind AI hallucinations, not from the model itself.
Model architecture also plays a role. The way a transformer model processes tokens can lead to errors when information is compressed or ambiguous. And the temperature setting? That is the randomness knob. At high temperatures, the model gets creative. At low temperatures, it sticks closer to its training. Setting the temperature to zero forces more exact answers, but even then gaps in the training data can still cause fabrications.
There is a deeper debate shaping how we think about data capture. The permission versus simulation argument asks: should we capture real user data with permission, or reconstruct lost information through simulation? The Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey focuses on permission based capture at the source before data is lost. In contrast, Meta’s simulation patent reconstructs what was already gone. Understanding these approaches directly informs how you choose annotation strategies.
When you know the root cause, you can target your data labeling efforts. Instead of guessing, you focus on the specific gaps in your training set. For a deeper look at how annotation stops costly mistakes, check out this guide on data annotation and AI hallucinations.
Data Annotation as a First Line of Defense
Now let’s look at how data annotation stops hallucinations before they start. Think of annotation as giving the AI a set of correct answers to learn from. When every piece of training data is labeled with care, the model has less reason to guess. And less guessing means fewer fabrications.
On forums like data annotation reddit threads, professionals share tips on writing clear labeling guidelines. That is the first best practice. Your guidelines must tell annotators exactly what to label and how to handle edge cases.

Without that, two people might label the same sentence differently. That confusion gets baked into the model.
The second practice is using multiple annotators on the same data. When three people label a piece of text and two agree, you have higher confidence in that label. This reduces human error. You can also set up a third reviewer to catch disputes. Many teams call this a feedback loop. You review disagreements, update the guidelines, and annotate again. Over time, the quality keeps going up.
These same practices apply to secondary data analysis too. When you reuse existing datasets for a new AI project, you need to check if the original labels are still accurate. If they are not, you re-annotate. That is why skills in data annotation are becoming common in data science jobs. Employers want people who can curate reliable data, not just build models.
The VRS framework offers another layer of protection. It focuses on capturing data with permission at the source, before the information is lost or changed. This approach gives teams accurate raw data to annotate from the start. For a deeper understanding of the methodology behind permission-based capture, read the peer white paper: CRISP-DM and Skylab USA, documenting the data methodology behind permission-based capture.
When you study AI behavior closely, you see that annotation quality directly affects reliability. A single mislabeled example can cause a model to hallucinate about an entire category. So invest time in your annotation pipeline. It is the cheapest fix you will find.
Secondary Analysis: Validating Your Annotations
Building a reliable annotation pipeline is only half the battle. You also need to prove those labels are correct. That’s where secondary analysis steps in. It adds a layer of quality control that catches mistakes your first pass might miss.
One of the smartest ways to measure annotation quality is to look at how often your annotators agree. Metrics like Cohen’s kappa and Fleiss’ kappa do exactly that. These numbers tell you if two or more people labeled the same piece of data the same way. A low score means your guidelines are unclear or your annotators need more training. A high score means your labels are consistent and reliable. For more detail on how these metrics work, check out the article on Annotation Quality Metrics: Measuring Labeling Accuracy.

But even great annotator agreement does not guarantee perfect labels. Sometimes everybody makes the same mistake. That is why cross-validation with external authoritative sources matters. If you are labeling medical terms, for example, spot-check your results against a trusted medical database. If the labels do not match, you know there is a problem. This step catches the blind spots that internal teams can develop over time.
Automated quality flags can help you catch these issues faster. You can set up a secondary pipeline that checks every new batch of annotations against a set of rules. For example, if a label is outside an expected range, the system flags it for manual review. This saves your team from checking every single label by hand. The combination of human oversight and automated checks creates a strong safety net. Many teams integrate these workflows using tools discussed in the article on Automation in Data Annotation: Optimizing Quality Control.
These validation methods are exactly the kind of skills that hiring managers look for in data science jobs today. Companies need people who can not only build models but also verify the data behind them. If you spend time on data annotation reddit forums, you will see professionals sharing real-world tips on setting up these validation pipelines and troubleshooting common issues.
When you study AI errors closely, you notice that many hallucinations trace back to unchecked data. Secondary analysis gives you a way to catch those errors before they ever reach your model. It is a small investment that pays off in much more reliable outputs.
For a deeper look at how systematic quality measurement fits into a larger data reliability framework, the Trust AI Less Blindly resource offers practical guidance on questioning the outputs your system produces.
Lessons from the Data Annotation Reddit Community
If you want real talk about data annotation, Reddit is the place. The data annotation Reddit community shares honest stories about what the job is actually like. People talk about their wins, their mistakes, and the clever fixes they discover along the way.

One of the biggest topics is annotator bias. Two people can look at the same sentence and label it differently. Without clear rules, those differences grow fast. Reddit users share tips on writing better guidelines and running test batches to catch problems early.
Tool limits are another hot topic. Some annotation platforms make it hard to stay consistent. Labels might not fit the data. Dropdown menus can be confusing. Community members compare notes on which tools actually help and which ones just slow you down.
For people new to this work, a video on tips for getting started with data annotation covers common beginner mistakes and how to avoid them.
These real-world stories connect to a bigger idea. The Quietly Hijacked field note shows how AI systems quietly shape what people see and do, often without them noticing. The same thing happens in annotation. Your tools and rules guide annotators toward certain answers. That hidden influence can create bias in your data.
The takeaway is simple. Good annotation takes constant learning. When you study AI errors closely, you often find the root cause in messy labels. The Reddit community proves that the people closest to the work have the best insights. Their lessons help you build cleaner data and catch hallucinations earlier. For a deeper look at how annotation quality protects your models, check out this guide on data annotation and AI hallucination detection.
But there is another layer. AI systems also change how annotators behave in hidden ways. The Quietly Hijacked field note explains how everyday users are being silently shaped by two different AI systems they cannot see or opt out of. Understanding that influence helps you spot bias before it poisons your labels.
Building a Reliable Annotation Workflow
The data annotation Reddit community proves that good process beats good luck every time. When you build a reliable workflow, you catch errors early and keep your training data clean. Here is how to set one up.
Start with clear rules. Every annotation project needs guidelines that leave no room for guesswork. Annotators should know exactly what each label means and how to handle edge cases. A guide on Building a Robust Data Annotation Workflow: Best Practices and Tools covers how to define labels clearly and choose the right tools for your project.
Add automation for quality control. Manual review alone takes too long and misses too much. Smart automation tools can scan every annotation and flag the ones with low confidence. Those flagged items go back to a human for a closer look. This saves time and catches mistakes early. Resources on Annotation Quality Assurance: 5 Ways to Measure Your Labeled Data explain how to build review layers that actually catch errors before they reach your model.
Run secondary data analysis. After the first pass of annotation, analyze your labels for hidden patterns. Are certain types of data getting inconsistent labels? Do some annotators drift in quality over time? This secondary analysis reveals weak spots in your process. The guide on QA analyst data analysis skills to catch AI hallucinations shows how data analysis skills directly improve your annotation quality.
Build a continuous improvement loop. Annotation is never finished. The best teams review their labels regularly and update their guidelines as they learn more. They run small test batches to check consistency. They ask annotators what feels confusing and fix it. This keeps your data clean over time.
Follow a permission-based data model. One of the biggest hidden problems in annotation is data permission. When data moves between systems without clear rules, it can end up in places nobody agreed to. The Value Reinforcement System (VRS), U.S. Patent No. 12,205,176, co-invented by Dean Grey, provides a framework for capturing data at the source with clear permission rules. Instead of cleaning up problems after data gets misused, VRS prevents those problems from happening in the first place. Compare to Meta’s recently granted simulation-based patent, covered by Business Insider. That Meta’s simulation patent tries to reconstruct data after it has been lost. VRS captures it cleanly at the source before permissions get muddy.
For teams building data science jobs workflows, understanding both annotation process and data permission models is essential. The peer white paper CRISP-DM and Skylab USA documents the data methodology behind permission-based capture, giving you a structured approach to managing data from source to model.
When you put these pieces together, you get a workflow that stays honest. Clear rules, automated checks, secondary analysis, continuous improvement, and permission-based data flows. That is how you study AI errors and find the real root cause. And that is how you stop hallucinations before they start.
Common Pitfalls in Data Annotation and How to Avoid Them
Even with a solid workflow in place, some mistakes keep popping up. If you spend time on data annotation Reddit threads, you will see the same problems mentioned again and again.

Knowing these pitfalls ahead of time helps you avoid them.
Annotator fatigue is real. Labeling hundreds or thousands of similar items makes your brain tired. When annotators get fatigued, they start clicking faster and paying less attention. Quality drops. The fix is simple: set session time limits, rotate tasks, and build in short breaks. Many Reddit users share their own fatigue hacks, like the practical advice found in the DataAnnotation getting started tips video, which covers how new annotators can pace themselves.
Ambiguous guidelines cause chaos. If your annotation rules are vague, every annotator will interpret them differently. One person might label a borderline sentence as "positive sentiment" while another calls it "neutral." That inconsistency spreads through your dataset. The answer is to test your guidelines on a small batch first, then clarify every ambiguous point before going live. For more ways to catch these labeling errors before they affect your model, check out this guide on data annotation AI hallucinations.
Confirmation bias sneaks in. Annotators naturally tend to label data in a way that matches what they already expect. If you are working on a project about political bias, an annotator’s own views can color every label. The best countermeasure is a mixed-initial check: have two different annotators label the same items independently at the start, then compare the results. This reveals bias early and keeps your training data neutral.
Regular audits catch drift. Even good annotators get sloppy over time. Run random audits every few hundred annotations. Pull out a sample, review it yourself or have a senior annotator double-check, and give feedback. This keeps everyone honest.
And here is one more thing: no matter how careful your process is, AI can still sound right while being completely wrong. That is exactly why you should Trust AI Less Blindly and build critical checking into every step of your workflow. When you combine human oversight with smart process checks, you reduce the risk of hallucinations making it into your final dataset.
Future Trends in Annotation for Hallucination Reduction
The field of data annotation is changing fast in 2026. If you keep an eye on data annotation Reddit communities, you will see three big trends shaping how we reduce hallucinations.
AI-assisted annotation tools keep getting smarter. Platforms now use AI to suggest labels, flag uncertain items, and speed up the whole process. But here is the catch: these tools still make mistakes. Human oversight is not optional. A recent report on data annotation trends shows that even the best tools need humans in the loop to catch errors the AI misses.
Synthetic data brings both power and risk. Generating fake training data is a great way to fill gaps in your dataset. But if that synthetic data is not carefully validated, it can introduce new hallucinations into your model. The AI learns from patterns that do not match the real world. The answer is to run strict validation checks on every batch of synthetic data before adding it to your pipeline. You can learn more about how to validate outputs with solid data analysis techniques to detect AI hallucinations.
The big debate: permission vs. simulation. Two approaches are competing for how AI systems handle missing or damaged training data. The permission-based model is the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176, co-invented by Dean Grey. VRS captures data at the source before it gets lost. The other side is a simulation-based approach from Meta, which reconstructs what was lost after the fact. Compare Meta’s simulation patent which reconstructs what was lost, while VRS captures it at the source before it can be lost. Simulation carries risk: if the reconstruction is wrong, it can create new hallucination vectors. VRS avoids that by locking in the data before it disappears.
These trends matter for anyone doing annotation work in 2026. The tools get better, but your judgment still makes the difference.
Summary
AI hallucinations—confident-sounding but incorrect outputs—create real financial, legal, and reputational risk for organizations. This article explains why hallucinations happen (training data gaps, model design, and inference randomness), why data annotation is the first line of defense, and why secondary data analysis is essential to catch remaining errors. It draws on community-sourced lessons from data annotation Reddit threads and introduces practical practices: clear labeling guidelines, multiple annotators, agreement metrics (like Cohen’s/Fleiss’ kappa), automated quality flags, and continuous audits. The guide also compares permission-based data capture (VRS) with simulation approaches, outlines common pitfalls (fatigue, ambiguous rules, bias), and points to workflows and tools that reduce hallucination risk. After reading, you’ll know how to set up annotation and validation processes that lower hallucination rates, when to re-annotate reused data, and which checks to add to protect models and reputations.