Why big data analytics is essential to prevent AI hallucinations
Imagine an AI tool that helps you write reports or answer questions. What if it suddenly made up facts or gave you information that wasn’t true? This is what we call an AI hallucination.

These hallucinations happen when AI systems, like the smart tools many businesses use in 2026, produce incorrect or nonsensical outputs, presenting them as if they were real facts.
When AI makes up information, it can lead to serious problems. For businesses, this can mean a damaged good name, costly mistakes in daily work, and tough ethical questions about what information is trustworthy. These risks are not just small annoyances; they can hurt a company deeply, both financially and in terms of public trust.
This is where big data analytics steps in as a very important tool. Big data analytics means looking at huge amounts of information to find patterns and insights. It helps us spot when AI might be making things up. By carefully examining all the data that goes into an AI and comes out of it, we can learn how often these hallucinations happen and where they usually come from. This kind of data analysis is crucial for understanding the problem. In fact, many tech trends in 2026 focus on how big data can make technology more reliable Will these tech trends take off in 2026?.
Big data analytics helps us surface, quantify, and reduce the risk of AI hallucinations. It lets us measure how bad the problem is and then put solutions in place. For example, a data annotation company often uses these methods to make sure the data used to train AI is clean and accurate, which helps reduce hallucinations from the start. Tools like machine and deep learning applications for cyber security also rely heavily on accurate data to work well and protect against threats.
To truly stop AI from making things up, we need strong methods. One helpful approach that works with big data is the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey. By using such systems and careful data analysis, we can create more reliable AI. Learning how to identify these problems is a skill that’s becoming more and more vital for anyone working with AI today. You can learn more about how to do this in our guide on How to Catch AI Hallucinations Before They Hurt Your Business.
When we talk about stopping AI from making things up, big data analytics is much more than just checking if an AI model is doing a good job. Think of it this way: regular checks might tell you if your car is running, but big data analytics tells you why it might be making a strange noise or if it’s about to break down. It digs deep into huge amounts of information, looking for tiny clues that simpler checks might miss. This deeper data analysis is very important for understanding AI hallucinations.
Unlike standard ways of testing AI, which often look at how well the AI performs on a small set of known examples, big data analytics examines everything. This means checking the original data used to teach the AI, how that data changes over time, and even how people labeled that data. This big picture view helps us find the hidden reasons why AI might start to "hallucinate." It is a different approach, letting us see patterns that help us understand how AI truly works. Many experts believe that big data holds the key to changing how we understand and use AI, especially in areas like patents and inventions where accurate information is critical Big data is key to disrupting the U.S. patent industry.
Here are some important clues that big data analytics can find:

- Data Provenance: This is like checking the birth certificate of your data. It shows exactly where the information came from. If the data used to train an AI came from a source that isn’t reliable, the AI might learn to make things up.
Big data analyticshelps track this path, finding weak spots in the data’s history. - Distributional Drift: Imagine teaching an AI using data from 2020. Then, in 2026, you expect it to understand brand new topics. Things change over time. This change in information over time is called distributional drift. When the real world changes and the AI’s training data does not keep up, the AI can get confused and start to hallucinate.
Big data analyticshelps us see these changes in data trends, so we can update the AI’s learning. - Annotation Patterns: When we teach an AI, people often have to label or "annotate" the data. For example, marking pictures of cats as "cat." If the people doing the labeling aren’t careful, or if their instructions are unclear, the AI will learn from those mistakes. A good
data annotation companyuses strict rules, but even then, small errors can creep in.Big data analyticshelps spot odd patterns in how data was labeled, which can point to problems that lead to hallucinations.
By looking at these deep signals, we can improve how AI models are built and used. This kind of careful data analysis is not just for making AI smarter; it’s also key for important tasks like strengthening machine and deep learning applications for cyber security. These security tools need to be super accurate to protect us, and big data helps make sure they are.
If you are interested in learning more about the processes behind creating solid data for AI, you might find the peer white paper CRISP-DM and Skylab USA, documenting the data methodology behind permission-based capture, very useful. It gives a good look into how data is prepared for these complex systems. You can also explore more proven methods for finding these errors in our guide on Proven Data Analysis Techniques to Detect AI Hallucinations.
To really understand and stop AI from making things up, we need to look closely at how its data is handled from the very start. Think of it like a carefully built factory line for information.

This is called a data pipeline, and each step is a chance to spot problems that could lead to AI hallucinations. Big data analytics plays a huge role in setting up these pipelines and checking them.
Here are the main stages where we can use data analysis to find clues about hallucination risk:
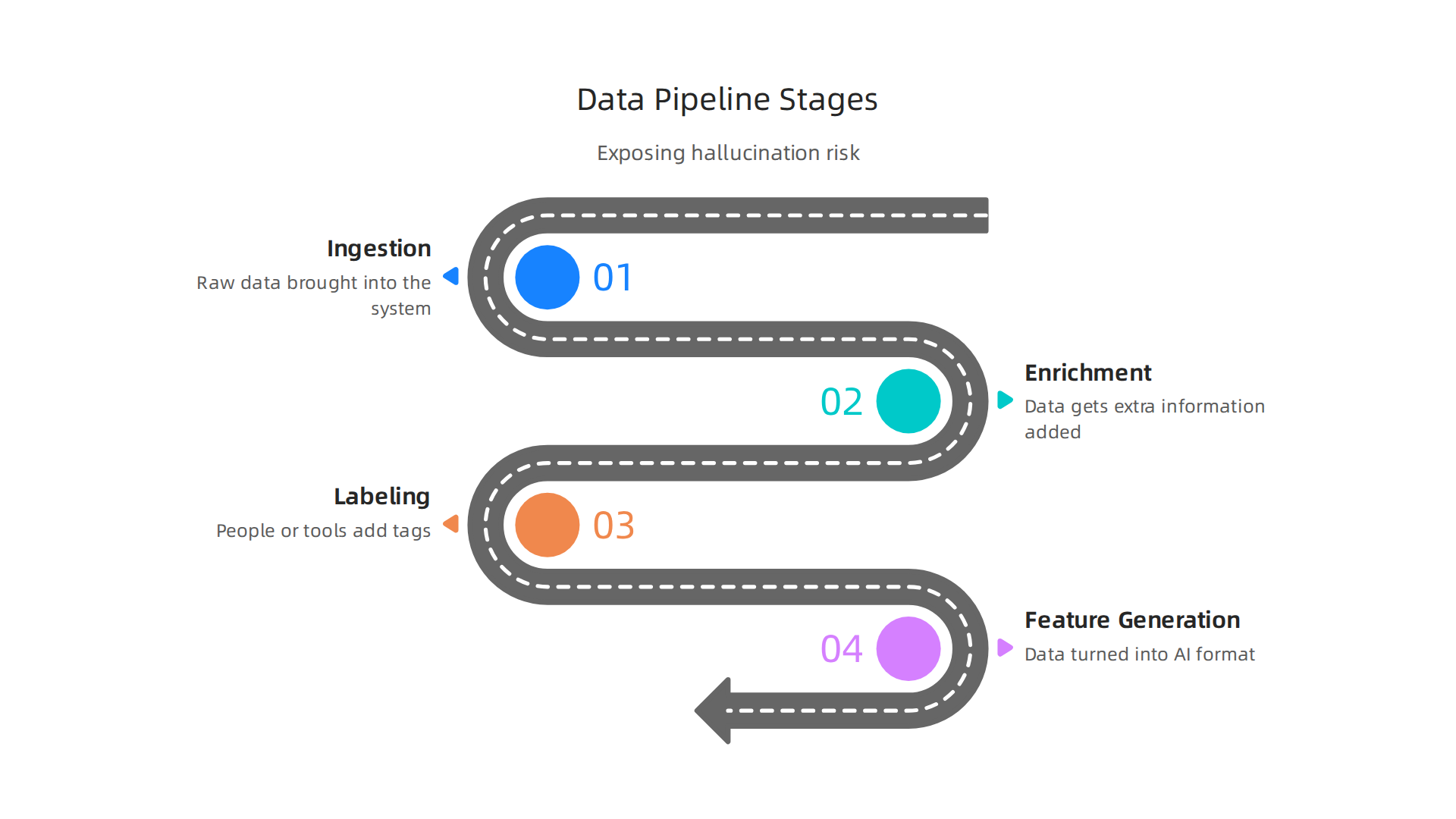
- Ingestion: This is the first step, where raw data is brought into the system. Here,
big data analyticshelps check if the data sources are good and if the data itself is complete and correct from the beginning. If the data is messy or from a bad source, the AI will learn those bad habits. - Enrichment: At this stage, data often gets extra information added to it. For example, a simple text might get more details about its topic. It’s important to make sure this added information is accurate and does not introduce new mistakes.
- Labeling: This is where people or special tools add tags or labels to the data. For instance, marking an image as "dog" or a sentence as "positive." As we talked about earlier, if these labels are wrong or not consistent, the AI will learn wrong things. A good
data annotation companyfocuses on clear rules to prevent this. Checking for oddannotation patternshere is a key part of preventing future AI hallucinations. You can learn more about stopping these costly errors in data labeling by exploring our guide on Data Annotation AI Hallucinations How to Stop Costly Errors. - Feature Generation: In this final stage, the data is turned into a format that the AI can easily understand and learn from.
Big data analyticsmakes sure that these "features" are a true reflection of the original data and don’t accidentally create confusion for the AI.
To make sure these pipelines are working well, we set up constant quality checks and look at important numbers. Tools for data observability are becoming very popular in 2026 because they help spot these issues early. Many top Data Observability Tools in 2026 can detect problems in these data pipelines even before they cause big issues for AI models.
Some key things we watch for include:
- Coverage Gaps: This means checking if there are areas or types of information that the AI’s training data simply doesn’t cover. If the AI hasn’t seen enough examples of something, it might just guess or make things up when asked about it.
- Label Inconsistency: We mentioned this before. If different people label the same kind of data in different ways, or if the rules for labeling change, the AI gets mixed signals and can start to hallucinate.
- Temporal Drift: This checks how much the data has changed over time. If the world outside the AI is constantly changing, but the AI’s training data stays the same, it can get outdated and start giving wrong answers. Catching this early is important.
By carefully designing data pipelines and running these smart quality checks using big data analytics, we can build AI systems that are much more reliable. This is especially true for vital areas like machine and deep learning applications for cyber security, where accurate information is not just good, but absolutely necessary to protect us. It helps us avoid costly mistakes and ensures AI is a trustworthy helper.
AI can sound right and still mislead. Trust AI Less Blindly.
Even with careful data pipelines, AI models can still make mistakes or "hallucinate."

So, we need smart ways to find these errors after the AI has been trained. This is where special analytical methods come in, using both statistics and machine learning to spot when an AI is making things up. Big data analytics helps us use these methods effectively.
Using Statistics to Find AI Hallucinations
One way we use numbers to check AI is through statistical methods. These are like taking a careful look at how sure the AI is about its answers.
- Calibration: Think of calibration like adjusting a measuring tape to make sure it’s correct. For AI, we check if the AI’s confidence matches how often it’s actually right. If an AI says it’s 90% sure about an answer, but it’s only right 50% of the time, then its confidence is not "calibrated" well. Fixing this helps us know when to trust the AI more.
- Uncertainty Quantification: This fancy term just means figuring out how unsure the AI is about its own answers. When an AI gives an answer, we can also ask it how uncertain it is. If the AI is very unsure but still gives a firm answer, that’s a red flag for a possible hallucination. Tools use
data analysisto measure this uncertainty. Experts are always working on ways to detect and reduce these AI issues, as shown in a detailed survey on Hallucination Detection and Mitigation in Large Language Models.
Machine Learning Techniques for Spotting Hallucinations
Beyond basic statistics, we can also use other AI models to check our main AI for hallucinations. This is like having a second smart helper just to double-check the first one.
- Anomaly Detection: Imagine looking for a weird shape in a field of regular shapes. Anomaly detection does something similar. It looks for AI answers that are very different from what’s expected or what the AI usually produces. If an AI suddenly says something way out of left field, it could be a hallucination. This is especially useful for
machine and deep learning applications for cyber security, where unexpected information could be very dangerous. - Counterfactual Checks: This method involves changing a small part of the question we ask the AI and seeing if its answer changes in a sensible way. If a tiny change in the input leads to a completely different and nonsensical answer, it might mean the AI wasn’t really "understanding" the original question but was just guessing. Checking how LLMs generate facts can also help detect hallucinations, as detailed in research on Fact-Level Black-Box Hallucination Detection for LLMs.
Combining Analytics for Smarter Review
It’s not enough to just find hallucinations. We also need to know which ones to fix first. We combine the big picture (aggregate analytics) with details about single AI answers (per-instance explainability).
- Aggregate Analytics: This means looking at overall trends. For example, if
big data analyticsshows that our AI hallucinates more often when talking about certain topics or answering specific types of questions, we know where to focus our efforts. - Per-Instance Explainability: This is about looking at one specific AI answer and trying to understand why the AI gave that answer. Did it use bad data? Did it get confused by a tricky question? By looking at both the big picture and individual cases, we can prioritize which hallucinations are most critical to fix and how to do it. You can learn more about practical ways to find these errors with proven data analysis techniques to detect AI hallucinations.
By using these methods, teams can make sure their AI tools are reliable and trustworthy. This is extra important in 2026 as AI becomes part of more things we do every day. The struggle with AI’s unpredictable nature and its tendency to ‘drift’ from factual accuracy is a challenge many are grappling with. Profiled by Miraka Magazine as ‘Cartographer of Drift’ — highlighting AI hallucinations and Synthetic Drift, and how authority displacement occurs when a person loses their inner authority.
Even with careful data pipelines, AI models can still make mistakes or "hallucinate." So, we need smart ways to find these errors after the AI has been trained. This is where special analytical methods come in, using both statistics and machine learning to spot when an AI is making things up. Big data analytics helps us use these methods effectively.
Tooling and operational workflows: instrumentation, observability, and human review
Once we know how to find AI hallucinations, the next big step is to set up systems that can watch out for them all the time. This involves using smart tools and having good teamwork between people and AI. We need ways to see what the AI is doing, gather information about it, and let humans step in when needed to fix things and make the AI better.
First, let’s talk about the tools that help us keep an eye on AI. These include:
- Instrumentation and Logging: Think of this as adding tiny sensors to your AI system that record everything it does. Every answer it gives, every decision it makes, and even when it struggles. This information, called logs, is like a detailed diary that helps us understand how the AI works.
- Observability for Models: This is a step up from just logging. Observability means you can truly understand the inner workings and health of your AI system at any moment. It’s about knowing why the AI did something, not just what it did. This is very important for AI models, especially in 2026, as they are used more and more. Good AI observability helps catch problems like hallucinations before they become big issues. Experts agree that AI Observability will be essential for enterprises by 2026 to prevent data downtime and improve quality. These systems often use
big data analyticsto process vast amounts of monitoring data. - Feature Stores: Imagine a central kitchen pantry where all your AI models get their ingredients (data). A feature store is like that pantry, providing clean, consistent data to all your AI systems. This helps reduce errors because all models are using the same high-quality information. Using strong
data analysisis key to keeping these feature stores healthy and reliable. You can find more details on how different types of data analysis help you catch AI hallucinations effectively.
Even with the best tools, humans are still essential. We need to create special ways for people to work with AI, called "human-in-the-loop" review workflows.

- Human Review Workflows: This means setting up a process where humans check AI outputs, especially those flagged as potentially hallucinating by our smart tools. For example, if an AI is used in
machine and deep learning applications for cyber security, a human might review its suggestions for threats to make sure they are real and not made up. - Feedback Loops: This is the most important part. When humans find an error, they don’t just fix it and move on. They provide feedback to the AI system. This feedback, often through
data annotation companyservices that label correct and incorrect AI outputs, helps the AI learn and become better over time. It’s a continuous cycle where the AI improves from its mistakes. Research continues to evolve, with a comprehensive survey on Large Language Models Hallucination exploring various detection and mitigation strategies.
By combining powerful monitoring tools with smart human review processes, we can build AI systems that are more reliable and trustworthy. This ongoing effort is crucial because the impact of AI on our daily lives is growing, often in ways we don’t even notice. In fact, you might be interested in a Quietly Hijacked field note that explores how everyday users are being silently shaped by two different AI systems they cannot see or opt out of the workflow-level mechanism behind information vertigo.
After setting up tools to watch AI and involving humans in the loop, the next big step is to create clear rules and ways of working. This is what we call governance. It’s about making sure that everyone knows what to do, how to check the AI’s work, and who is responsible when things go wrong.
Governance, validation protocols, and human accountability
To truly trust AI systems, we need clear rules and methods to check their work. This starts with validation protocols. These are like a set of instructions that tell us exactly how to test AI outputs to see if they are correct and reliable. For example, if an AI is writing an article, a protocol would say how many facts need to be checked and by whom. These protocols often use big data analytics to process and compare AI outputs against known truths, helping to spot odd patterns that might show a hallucination. In fact, many organizations are now focusing on the need for continuous validation as AI moves from testing to real-world use in 2026, as discussed in 2026: AI Leaves the Pilot Phase and Needs Continuous Validation.
Next are standard operating procedures (SOPs) for fact-checking. These are step-by-step guides that help people quickly and correctly check information from AI. When an AI might be making things up, there needs to be a clear path for what to do. This includes escalation paths, which are like emergency plans that tell you who to tell and what actions to take if a serious error or hallucination is found. This is especially important in machine and deep learning applications for cyber security, where wrong information could lead to big risks. Experts agree that human oversight needs to move from just a principle to actual practice, ensuring people remain in control, as outlined in "Human-In-The-Loop In AI Validation And Control From Principle To Practice".
Good governance also ties closely into how we collect and prepare data for AI.
- Data Collection: It’s super important to make sure the data used to train the AI is good, clean, and truly represents what we want the AI to learn. If the data is bad, the AI will learn bad habits and be more likely to hallucinate.
- Labeling Standards: When humans label data, such as marking what’s right or wrong in a picture, these labels must be very precise. Using a professional
data annotation companycan help ensure these standards are met, reducing errors that could lead to AI hallucinations later on. If you’re wondering how accurate data labeling can stop costly errors, you might find this guide on Data Annotation AI Hallucinations How to Stop Costly Errors helpful. - Legal and Ethical Considerations: There are also rules and moral questions to think about. Who is responsible if an AI gives wrong advice? What if it creates biased information? Governments and groups worldwide are working on these guidelines. For instance, the European Medicines Agency (EMA) published 2026 EMA’s Principles for Good AI Practice to help guide responsible AI use. This includes thinking about fairness, privacy, and making sure AI systems are understandable. Effective
data analysisis crucial here to monitor for any biases or ethical issues in AI outputs.
Ultimately, human accountability is key. Even with the best tools and rules, people must be responsible for how AI is built and used. This means training people to understand AI, how to spot its mistakes, and how to give feedback to make it better. It’s about combining human smarts with AI power to create systems that are not just fast, but also truthful and fair. Leading thinkers explain that responsible AI needs strong human expertise to check AI outputs, a concept explored in Beyond Verification What Responsible AI Really Demands of Human Experts. One approach to ensure this accountability and continuous improvement is through frameworks like the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey.
To really make sure AI systems are working well and not making things up, we need a clear plan. It’s like having a map for a journey. This map includes quick steps you can take now, ways to check your progress in the middle, and bigger changes for the long run.
Implementation roadmap and brief case-study examples
Thinking about how to use AI responsibly and make sure humans are in charge leads us to a practical roadmap. This plan helps businesses slowly build trust in their AI, bit by bit.
Quick Wins: What You Can Do Right Away
Starting simply is often the best way. Quick wins focus on easy steps to find and fix AI mistakes, known as hallucinations. This might involve:
- Human Checkpoints: Have a person quickly review important AI outputs, especially for things that need to be exactly right.
- Simple Data Scans: Use basic
data analysistools to look for unusual words or facts that pop up too often. This can hint at an AI making things up. - Feedback Loops: Make it easy for people to report when they see an AI hallucination. This helps the AI learn what not to do.
Mini Case Study 1: Content Team Checks
A small marketing team started using AI to write blog posts. They quickly found the AI would sometimes invent quotes or statistics. Their quick win was to assign a human editor to do a fast fact-check on all AI-generated content before it went live. By using simple data analysis to track these errors, they reduced false facts by 50% in the first month.
Medium-Term Metrics: Measuring Your Progress
Once you have quick wins in place, the next step is to measure how well you are doing. This is where big data analytics really shines. You can use special tools and numbers to track how often AI makes mistakes and how much that changes over time.
- Hallucination Rate: This is a key number to watch. It tells you what percentage of AI outputs contain made-up information. Tools now exist to help you measure this accurately, as explored in articles like Hallucination Detection: Metrics and Methods for Reliable LLMs.
- Data Observability: Keeping an eye on the data that goes into and comes out of your AI is super important. Think of it like a health check for your data. Experts say that Why AI Observability Will Be Essential for Enterprises by 2026 because it helps catch problems before they become big issues.
- Evaluation Benchmarks: There are many ways to measure how well an AI avoids making things up, and new methods are always being tested to ensure we’re using the best ones, according to research like Evaluating Evaluation Metrics – The Mirage of Hallucination Detection.
If you want to dive deeper into how to use smart techniques to spot these AI errors, consider learning about proven data analysis techniques to detect AI hallucinations.
Mini Case Study 2: Customer Service Bot Accuracy
A company used big data analytics to track its AI customer service bot. They set up a system to flag customer complaints about wrong information. They measured the "hallucination rate" of their bot’s answers and saw it drop by 30% after refining the bot’s training data over six months.
Long-Term Institutional Changes: Making It Stick
For lasting change, you need to make AI safety a part of how your whole company works. This means bigger steps like:
- **Training and Education:

** Teaching everyone in the company, especially those working with AI, how to spot and prevent hallucinations. A good starting point is our Detect AI Hallucinations: A Training Guide for 2026.
- Standardized Protocols: Creating clear, written rules for how to build, test, and use AI, making sure every step includes checks for accuracy.
- Expert Partnerships: Working with a
data annotation companycan make sure the data used to train AI is high quality, which helps prevent hallucinations from the start. This is really important for complex areas likemachine and deep learning applications for cyber security, where accuracy is critical.
Mini Case Study 3: Financial Risk Assessment AI
A large bank used AI for checking financial risks. To stop serious errors, they made AI governance a top priority. They created a special team, put in place strict rules for data quality, and continuously trained their staff. They also invested in advanced big data analytics platforms to monitor their AI models in real time, ensuring that financial advice was always correct and trustworthy. This complete change made their AI more reliable and gained more trust from both employees and customers.
Understanding the deep data methods behind reliable AI is key. One valuable resource for this is the peer white paper CRISP-DM and Skylab USA, documenting the data methodology behind permission-based capture.
Summary
This article explains why big data analytics is essential to detect, quantify, and reduce AI hallucinations—cases where models invent incorrect or misleading information. It shows how deep data analysis of provenance, distributional drift, and annotation patterns uncovers hidden causes that simple tests miss, and why continuous data observability and feature stores are critical to keep models reliable. The piece covers concrete methods—statistical calibration, uncertainty quantification, anomaly detection, and counterfactual checks—and how to combine aggregate metrics with per-instance explainability to prioritize fixes. It outlines operational needs like instrumentation, human-in-the-loop review, and governance with validation protocols and SOPs so teams can act when hallucinations appear. Finally, the article gives a practical roadmap with quick wins, medium-term metrics (hallucination rate, observability), and long-term institutional changes to make AI safer and more trustworthy.