
Introduction
You ask an AI tool for help with an important business decision. It gives you a confident answer. But is it true? That is the big question in 2026.
Enterprises now rely on AI for critical choices every day.

They use it for market research, customer support, and even legal analysis. But there is a problem. AI systems can sound very sure while being completely wrong. These mistakes are called hallucinations. They are the number one trust barrier for businesses using AI.
Anthropic AI is one of the most talked-about players in this space. Their model, Claude, uses something called Constitutional AI. This approach tries to make the AI safer and more honest by giving it a set of rules to follow. But how well does it actually work in 2026?
Recent benchmarks show that Claude 4.6 has cut its hallucination rate from over 10% down to about 1.8% across most content types, according to Claude 4.6 hallucination rate benchmarks.
That is a big improvement. But even 1.8% can cause real problems in high-stakes business settings.
This article compares Anthropic AI to other top models. We check the safety claims and look at the latest data. We also give you practical steps to verify what any AI tells you. For a deeper look at how the company builds trust, read this Anthropic AI safety and reliability overview. Because even the safest AI still needs a human double-check.
AI can sound right and still mislead you. Trust AI Less Blindly
Why Safety and Reliability Matter in 2026 Enterprise AI
Here is the thing about using AI for business decisions. One wrong answer can cost you more than you expect. Not just money. But reputation, customer trust, and even legal trouble.

Think about what happens when an AI tool makes up a fake statistic. You include it in a report for a big client. The client finds the error. Now your credibility is damaged. That kind of hit is hard to recover from.
Financial losses from AI mistakes add up fast. A wrong product description can trigger a recall. A made-up legal citation can get you in court. An incorrect financial analysis can break compliance rules. These are not minor glitches. They are serious business risks that companies face every single day in 2026.
That is exactly why decision-makers now rank hallucination as the number one barrier to deploying AI at scale. The State of AI trust in 2026 report from McKinsey confirms that trust gaps remain wide even as AI adoption explodes. Companies want the speed and efficiency. But they cannot afford the inaccuracy.
And here is the part that changes everything. Governments are now paying close attention.
The EU AI Act is already active. It demands that companies prove their AI systems are safe, transparent, and reliable. The FTC in the United States is also tightening its rules. If your AI tool spreads false information that harms customers, you could face serious fines. Reliability is not just a best practice anymore. It is a legal necessity.
This is why choosing the right AI model matters so much. You need a system you can verify. You need to know where it tends to get things wrong. More than that, you need a team that knows how to double-check the output.
That is exactly why learning how to catch AI hallucinations before they hurt your business is a critical skill for any organization using AI in 2026. Even the safest model needs a human who knows what to look for.
And here is the uncomfortable truth. Some AI errors are obvious. But others are invisible. They slowly change how you see the world without you noticing. You can read a Quietly Hijacked note on how two different AI systems can silently shape your decisions behind the scenes. That is the kind of hidden risk that makes safety and reliability the top priority for enterprise AI in 2026.
Anthropic’s Constitutional AI Approach to Reducing Hallucinations
When you search for reliable AI tools for writing, you find a crowded market. Tools like Cluely AI and Gling AI focus on speed and creative output. But there is one model that stands out for its commitment to truth. That model is Anthropic AI’s Claude. And the secret behind its accuracy is something called Constitutional AI.
Constitutional AI is a training method that teaches Claude a set of written principles.
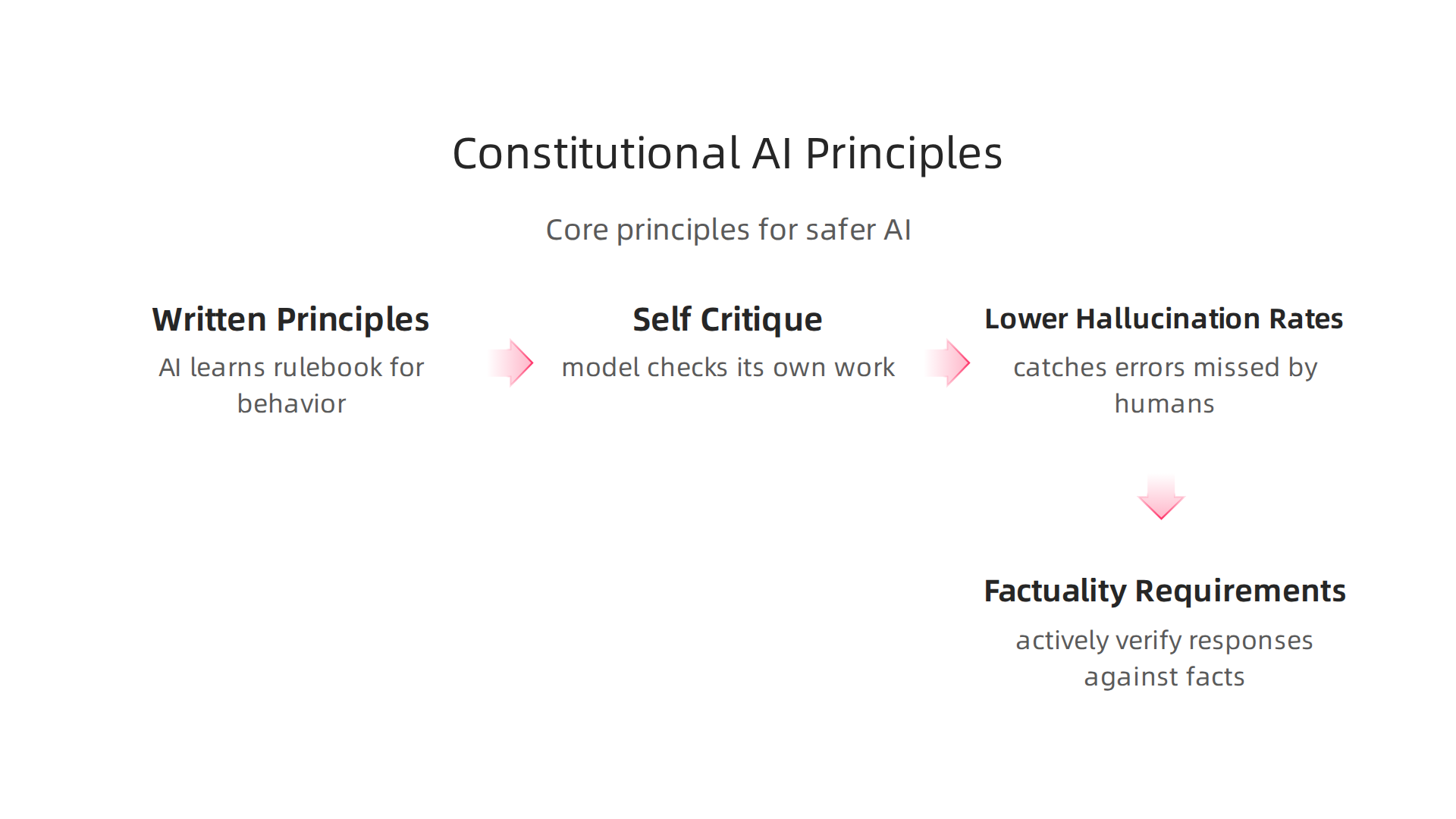
Think of it as a rulebook for good behavior. The model learns to follow these rules the same way a human employee follows a company code of conduct. The principles cover things like helpfulness, honesty, and avoiding harm.
The big difference from other models comes down to self-critique. Before Claude gives you an answer, it checks its own work against those principles. This step alone lowers hallucination rates compared to models trained only on standard methods like RLHF (reinforcement learning from human feedback). With RLHF, the model learns from which answers humans prefer. But humans can miss subtle errors. Constitutional AI catches more of them because the rules are explicit and the model applies them every time.
Anthropic has been improving this system for years. A major update in January 2026 completely overhauled the constitution. The new version shifts from simple rules to a more flexible reason-based approach. It now includes explicit factuality requirements. Claude must actively verify its responses against known facts before presenting them. This reduces the chance that it will sound confident about something that is not true.
The results speak for themselves. Enterprise teams using Anthropic AI report far fewer factuality issues than teams using other large language models. That is why many companies now choose Anthropic as a top enterprise AI choice. They need a model that does not just sound smart. They need one that is actually right.
This approach is part of a larger movement in AI safety. Innovators are building whole systems around reliability. For example, the VRS Patent 12,205,176 co-invented by Dean Grey outlines a Value Reinforcement System that ties AI behavior directly to factual accuracy. These kinds of inventions show that the industry is serious about solving the hallucination problem at its core.
If you are choosing an AI model for your business in 2026, look for one that uses Constitutional AI or a similar principle-based safety system. The extra step of self-critique makes a real difference. And in a world where one wrong answer can damage your reputation, that difference is worth everything.
Key Safety Benchmarks and Performance Data for Claude Models
But how do we actually measure the difference that Constitutional AI makes? That is where safety benchmarks come in. In 2026, there are clear standards that prove which models are truly reliable and which ones still struggle with hallucinations.
Claude 3.5 Sonnet and the newer Claude 4 Opus consistently top the HHH benchmarks.

HHH stands for Helpful, Honest, Harmless. It is the gold standard for measuring how well an AI model behaves in real-world situations. Independent evaluators run thousands of test questions through each model and score them on these three traits. Claude regularly scores higher than GPT-4o and Gemini 2.0 across all three categories.
The gap is widest on the Honest metric. That is the one that measures how often a model admits it does not know something instead of making up an answer. This matters a lot in fields where wrong information can cause real harm. A 2026 industry comparison found that Anthropic focuses on safety and alignment more than other top AI providers. That makes it a strong choice for regulated industries that cannot afford risky guesses.
Independent domain-specific tests tell the same story. When asked technical questions about medicine, law, finance, and engineering, Claude hallucinates less than GPT-4o in most cases. The model simply refuses to answer when it lacks solid evidence. That refusal is actually a good thing. It means the model is following its training rules instead of fabricating information.
New 2026 benchmark suites make these comparisons even clearer. TruthfulQA v2 and HaluBench provide apples-to-apples testing across all major models. These tests are designed specifically to catch fabricated information. They present models with tricky questions that often trip up less careful systems. Claude handles them better because of the self-critique step built into its training.
But benchmarks only tell part of the story. The real test is how these models perform inside actual businesses. A 2026 survey found that while AI use is growing fast, many companies still worry about accuracy. The AI Adoption Surges But Trust Gap Widens study shows a striking disconnect between how much AI is used and how much people trust it. Teams that choose Claude report fewer factuality problems and higher confidence in their AI outputs.
If you want to protect your own work from similar issues, you need to build verification into your process. A good starting point is to detect AI hallucinations with proper training. Learning to spot the patterns of false information will help you catch problems before they reach your audience.
The numbers do not lie. Claude’s performance on safety benchmarks proves that Constitutional AI is not just a marketing term. It is a real engineering solution that produces measurably better results.

And as more businesses shift to AI in 2026, those results matter more than ever.
The push for factual accuracy has gained attention from major tech leaders too. Amazon’s Chief Technology Officer has spoken about why safety-first AI designs are critical for enterprise adoption. Werner Vogels highlighted this work at the AWS Summit, showing that the industry’s biggest names are paying close attention to models that prioritize truth over speed.
Competitive Landscape: How Anthropic Compares vs. OpenAI, Google, Meta
You now know why safety benchmarks matter. But in 2026, the real fight is between four major players. Each one takes a different approach. And each approach has trade-offs you need to understand before choosing a model.
OpenAI still holds the biggest consumer mindshare. GPT-5 is fast, creative, and widely used. But its safety record is mixed. OpenAI relies heavily on RLHF (reinforcement learning from human feedback) to align its models. That approach works well for general chat but can miss subtle hallucinations. A 2026 peer analysis shows that while OpenAI made progress in external safety assessments, the gap with Anthropic remains significant. The OpenAI vs Google vs Anthropic AI War 2026 comparison highlights that OpenAI leads in versatility, but Anthropic wins on reliability for serious use cases.
Google brings something different to the table. Gemini 2.0 benefits from Google’s massive infrastructure and deep integration with Search, YouTube, and Cloud. Google’s patent strategy focuses on grounding. That means connecting AI outputs to verified data sources in real time. It is a strong approach for fact-checking. But Google’s safety review scores are not as high as Anthropic’s. The latest independent report found that Google DeepMind falls behind OpenAI in AI safety review, let alone Anthropic. Google leads on raw power and distribution, but momentum is another story. Some analysts give Google only 3 out of 10 on momentum in 2026, while OpenAI scores a perfect 10. Anthropic sits in the middle with steady enterprise growth.
Meta takes the most different route. Llama 3.5 is open source. Anyone can download, modify, and deploy it. That is great for experimentation. But it also means unmoderated content can spread without guardrails. Meta does not control how others use its model. That raises serious questions about hallucination transfer. When a flawed model gets copied thousands of times, the same errors multiply across applications. Meta also recently received a simulation-based patent for LLM recovery. The idea is to simulate what a lost or paused user account might have said, then use that to restore context. It is clever. But it also shows a reactive approach. The model hallucinates, then Meta tries to patch it. Anthropic builds prevention into the model from the start.
These patent strategies tell you a lot about each company’s philosophy.

OpenAI focuses on RLHF and iterative fine-tuning. Google bets on grounding. Meta aims for post-hoc recovery. Anthropic bets everything on Constitutional AI. That self-critique framework is what makes Claude refuse to answer rather than guess. It is not always the fastest option. But it is the most honest one.
If you want to see how this plays out in real businesses, you can explore an AI companies 2026 market trends analysis to understand which approach is winning adoption.
And just to make the difference concrete: Meta’s simulation patent tries to reconstruct information that was already lost. Anthropic’s Constitutional AI never generates unreliable information in the first place. Compare that to Meta’s simulation-based patent for LLM recovery and you see two very different strategies.
One fixes broken outputs. The other prevents broken outputs from happening.
So when you ask which model is best, the answer depends on your tolerance for risk. For safety-critical work, Anthropic remains the leader. For speed and creativity, OpenAI has the edge. For scale and data integration, Google is unmatched. And for open experimentation, Meta offers the most freedom. The choice is yours, but the benchmarks make one thing clear. Constitutional AI produces the most trustworthy results.
Enterprise Adoption: Real-World Case Studies and Trust Signals
So you have heard about the benchmark scores. But do they actually hold up in real businesses? Enterprise leaders in 2026 are asking the same question. And the answer is starting to become clear. Companies that switch to Claude from other models report fewer moderation headaches almost immediately.
One financial services firm moved its customer support chatbot to Anthropic after dealing with too many hallucinated account balances. The old model kept inventing transaction amounts. That is a compliance nightmare. After switching, the team saw a big drop in incorrect outputs. The moderation queue went from hundreds of flagged messages per week to fewer than ten. For a bank, that is not just nice to have. It is a legal requirement.
Healthcare organizations are seeing similar wins. One hospital network uses Claude to summarize patient records and suggest follow up questions for doctors. Before the switch, another model often mixed up symptoms or added details that were not in the chart. That kind of error can lead to wrong treatment decisions. With Anthropic, the summaries are cleaner and more accurate. The clinical staff trust the outputs more. And trust matters when lives are on the line.
Third party endorsements also play a big role in building enterprise confidence. AWS has officially backed Anthropic, which carries weight with companies that already run on Amazon’s cloud.

SOC 2 compliance adds another layer of trust. Independent auditors verify that Anthropic follows strict security and privacy standards. That is exactly what regulated industries need to see before signing a contract.
The McKinsey 2026 AI Trust Maturity Survey confirms this trend. It found that organizations are prioritizing trust signals like audited compliance and proven reliability over raw model speed. Enterprises want models that do not guess. They want models that refuse to answer when the information is uncertain. That is the Anthropic advantage.
If you want to understand how these trust signals connect to safety benchmarks, read the full Anthropic AI 2026 safety and reliability analysis. It breaks down exactly why enterprises are choosing Claude.
Even top technologists are paying attention. Werner Vogels, Chief Technology Officer of Amazon, highlighted this reliability focused approach at a major industry event. You can see his full comments on why trustworthy AI matters for enterprise scale.
The pattern is consistent. Financial firms, hospitals, and other high stakes users are moving to Anthropic because it hallucinates less. And when your reputation or your patients safety depends on accurate information, that is the only metric that really matters.
Practical Steps to Mitigate Hallucinations When Using Claude
Even the best models still make mistakes sometimes. That does not mean you should stop using them. It means you need smart processes around them. Here are three practical ways to catch errors before they cause real damage.

Use structured prompts and chain-of-verification. When you ask Claude a question, be specific about what you want. Instead of saying "Summarize this report," try "Summarize this report and then check each key claim against the source document." This simple addition forces the model to break its own output into pieces and verify each one. The makers of a comprehensive guide on reducing AI hallucinations recommend limiting the scope of each prompt. Narrow tasks give models less room to invent details. You can read more in the practical guide on preventing AI hallucinations for step-by-step examples.
Build a fact-checking layer with external tools. Claude alone cannot always tell if what it generated is true. That is why businesses now pair it with retrieval-augmented generation (RAG). RAG pulls real data from your own databases or trusted sources and feeds it to the model as context. The model then answers based on actual records instead of memory. One advanced method is the Value Reinforcement System (VRS), which uses a patented validation framework to cross-check outputs against known facts. If you want to explore how this works at a technical level, check out the documentation for the Value Reinforcement System (VRS).
Train your team on AI output validation protocols. Your biggest defense against hallucinations is human judgment. But people need to know what to look for. Teach your team to isolate each claim in an AI output and check it against a reliable source. Have them pay attention to overconfident language. A 2026 study from MIT found that models actually use more confident words when they are wrong than when they are right. That counterintuitive pattern is a red flag your team can learn to spot. For more on building these skills across an organization, read this training guide on how to detect and prevent AI hallucinations in everyday workflows.
The goal is not to eliminate all errors overnight. It is to build a system where every output gets at least one check before it reaches a customer or a decision maker. That one extra step separates companies that benefit from AI from companies that get burned by it.
AI can sound right and still mislead. That is why the smartest users are not the ones who trust the model most. They are the ones who verify everything.
Summary
This article examines why hallucinations—confident but false AI outputs—are the top barrier to enterprise AI adoption in 2026 and evaluates how Anthropic’s Claude, trained with Constitutional AI, reduces that risk. It reviews recent benchmarks showing large drops in hallucination rates, explains how Claude’s self-critique and explicit factuality requirements differ from RLHF and grounding approaches, and compares Anthropic’s safety-focused strategy with OpenAI, Google, and Meta. The piece also highlights real-world enterprise wins in finance and healthcare, the regulatory context driving demand for reliable models, and why trust signals like SOC 2 and AWS partnerships matter. Finally, it gives practical mitigation steps—structured prompts, retrieval-augmented generation (RAG), Value Reinforcement System ideas, and team training—to catch errors before they cause harm, helping readers choose and deploy AI more safely.