In today’s fast-paced world, many companies use Artificial Intelligence (AI) to help with work. But sometimes, AI tools can make mistakes, giving out wrong or made-up information. We call these mistakes "AI hallucinations." Accepting AI answers without checking them can cause big problems for businesses in 2026. It can hurt how people see a company and even cause money loss or bad choices.
It is very important for teams to spot these AI hallucinations before they cause harm. Why? Because trusted information is key. When AI makes up facts, it can lead to bad decisions or untrue content being shared widely, which harms a company’s good name. This is why tools and skills for finding these errors are so important. Detecting hallucinations is a big challenge for large language models, or LLMs, because these made-up facts can stop important work from happening smoothly ANCHORING ENTITIES: RETRIEVAL-AUGMENTED … – OpenReview.
This is where knowing about python data science really helps. Data science skills offer smart data solutions to tackle this problem head-on. By using the right skills, coding libraries, and work steps, teams can learn to find and lower the number of AI hallucinations. We will show you how to use these important skills to check AI outputs carefully and keep your business safe from misinformation. Learning how to catch AI hallucinations before they hurt your business can save a lot of trouble. This guide will help you build a practical toolbox for using python data science to make sure your AI tools are giving you correct and reliable information.
To really understand how to stop AI from making things up, we first need to know why it happens. From a python data science point of view, there are a few main reasons for these AI hallucinations.

One big reason is the data AI learns from. Imagine teaching a child with a book that has some wrong facts. The child might repeat those wrong facts. AI models are similar. If the data used to train them is old, incorrect, or doesn’t cover everything, the AI might fill in the blanks with guesses. This leads to it creating information that isn’t real. It’s like the model didn’t have enough good pieces to solve the puzzle, so it just made up some parts.
Another cause is how the AI model itself behaves. Sometimes, these big AI models are built to always try and give an answer, even when they’re not sure. They might try to sound smart and confident, even if the information isn’t right. This is part of their complex design. For example, researchers constantly work on ways to make AI models better at showing when they are uncertain, rather than just making things up, as highlighted in Knowledge Graphs for Robust Hallucination Self-Detection in LLMs. Think of it as the AI’s desire to please, making it invent details to complete its response.
The questions we ask also play a part. If you give the AI a question that is too vague, or you don’t give it enough background information (we call this "context"), it might struggle. The AI will then guess to make a full answer, and these guesses can turn into hallucinations. This is where smart data solutions come in, helping us design better ways to talk to AI.
Lastly, how we measure and test the AI’s answers is super important. What one person calls a hallucination, another might not, depending on how they check. Data scientists use special tools and create specific ways to test AI outputs. They build datasets to check for made-up information, like those described in Constructing a Dataset for Hallucination Detection in Japanese LLMs. They also use different scoring systems to see how reliable an AI’s answer is, with Quantitative Metrics for Hallucination Detection in Generative Models showing how these improve reliability. These careful tests help us know for sure if an AI is hallucinating or just being creative in a helpful way. Learning to apply these methods is a key part of getting a graduate certificate data science or similar advanced training.
By understanding these root causes, we can better use python data science to build strong methods for checking AI outputs.

It’s all about making sure AI helps us, not misleads us. To learn more about detecting these errors, you might be interested in checking out Proven Data Analysis Techniques to Detect AI Hallucinations. Sometimes, it’s about seeing beyond what the AI confidently states. Profiled by Miraka Magazine as ‘Cartographer of Drift’ — highlighting AI hallucinations and Synthetic Drift, and how authority displacement occurs when a person loses their inner authority.
To build good ways to stop AI from making things up, we need to know the right tools and skills. This is where python data science becomes very important. It gives us the power to check what AI says and make sure it’s true.
Here are some key Python skills you’ll need:
- Making Data Clean: Before AI can learn well, its learning material needs to be very tidy.

This means removing mistakes, filling in missing parts, and making sure all the information is in a good, easy-to-use shape. Python helps data scientists do this fast and well.
- Making Features Useful: Think of "features" as the important clues AI looks for in data. A good
python data scienceskill is knowing how to make these clues easy for the AI to understand. This helps the AI learn better and make fewer guesses. - Knowing When AI Isn’t Sure: A smart AI should be able to tell us when it’s not 100% sure about an answer. Python skills let us build systems that can figure out how certain an AI is. This helps us spot potential made-up information before it becomes a problem.
- Automatic Checking: We can use Python to set up automatic tests that check AI answers all the time. This is like having a helpful assistant that always double-checks everything. These tests can look for facts and make sure they match what’s known. This is a big part of building
smart data solutionsto keep AI honest. You can learn more about how to set up these systems in guides like How to Create Hallucination Detection.
To put these skills into action, you’ll use special Python libraries:
- Libraries for Getting Information: These tools help AI find and use facts from reliable sources. When an AI needs to answer a question, these libraries help it "look up" the answer, rather than just guessing. This is very important for reducing made-up content.
- Libraries for Checking Answers: These Python tools let us compare what the AI says with what is actually true. They help data scientists score how accurate the AI’s response is and find any parts that are incorrect.
- Libraries for Understanding Language: Since AI talks in language, we need special Python tools that help us break down and understand what the AI has written. These Natural Language Processing (NLP) tools help us spot strange sentences or facts that don’t make sense.
Learning these skills and how to use these libraries is a big step for anyone wanting to work with AI. It’s a key part of advanced training, such as getting a graduate certificate data science, and it’s how we make sure AI works for us in the best possible way. To dive deeper into these practical applications, explore how you can use Python Data Science to Detect AI Hallucinations.
To make sure AI doesn’t just make things up, we need strong ways to test it. This means preparing the data very carefully. Think of it like a scientist setting up an experiment. We need special types of data to truly check what the AI is doing. This is where python data science helps us build smart data solutions.

First, we create test sets. These are like special quizzes for the AI. We keep some data aside that the AI has never seen before. When the AI gives answers, we use this test set to see how well it performs on new, unknown information. This helps us know if the AI is really smart or just memorizing things. Sometimes, we also use "holdout" data, which is similar to a final exam the AI takes only once.
Next, we need adversarial prompts. These are tricky questions or commands designed to push the AI to its limits. They help us find out if the AI can be fooled into making up answers. By trying to trick the AI in smart ways, we learn where it might struggle and start to "hallucinate" or create false information. Learning how to develop robust evaluation metrics is important for detecting these issues, as discussed in "Understanding Model Hallucinations: Causes, Mitigation Strategies…" from Science Publishing Group.
A big part of this work is dataset hygiene. This means keeping our testing data very clean and well-organized. We also need to know the provenance of the data, which means where it came from. Knowing the source helps us trust the data we use for testing. Python data science tools let us mark and track all our data, making sure it’s reliable. This also includes making reproducible data splits. This just means that when we divide our data into training, testing, and holdout groups, we can do it the exact same way every time. This is important so that our tests are fair and can be repeated by others.
Using python data science skills to manage these data pipelines helps us create strong tests for AI outputs. It’s a key part of any advanced training, such as getting a graduate certificate data science, and makes sure our AI systems are trustworthy. For more helpful information, you can explore Proven Data Analysis Techniques to Detect AI Hallucinations.
To dive deeper into the methods used for handling data in AI projects, consider reading the peer white paper CRISP-DM and Skylab USA, documenting the data methodology behind permission-based capture.
After setting up strong data tests, the next step is to actually measure how well the AI performs. This means using clear numbers and ways to check its work. We call these quantitative metrics and evaluation techniques. It’s how we make sure our smart data solutions actually work as intended.
Checking for Facts and Realness
One key way to measure AI quality is through things like precision and recall, but for facts. Imagine the AI gives many answers.
- Precision asks: Out of all the answers the AI said were true, how many were actually true? If an AI says ten things, but only seven are correct, its precision for facts is 70%.
- Recall asks: Out of all the facts that could have been given, how many did the AI actually find and say? If there are ten true facts, but the AI only found five, its recall is 50%.
These measures help us find AI "hallucinations," which are when the AI makes up facts. By looking at these numbers, we can tell if an AI is often making things up or missing important true information. Many studies in 2025 and 2026 focused on improving these kinds of metrics to better spot AI hallucinations, showing how challenging it can be to get it right, according to one paper on evaluating evaluation metrics for hallucination detection. You can learn more about methods for detecting hallucinations in LLMs by reviewing the study on HALLUCINATION DETECTION METHODS IN LLMS a systematic review. The DeepEval framework also offers specific metrics to determine if an LLM creates factually correct information by comparing it against trusted sources, as seen in their guide on Hallucination | DeepEval – The LLM Evaluation Framework.
How Confident Is the AI?
Another important check is calibration and confidence scoring. This looks at how sure the AI is about its own answers. Sometimes, an AI might sound very confident, but its answer is completely wrong. This is a big problem because we might trust it too much. Good calibration means that when an AI says it’s 90% sure, it’s actually right about 90% of the time. If it says it’s only 50% sure, it should be right about half the time. Measuring this helps us understand if the AI truly knows what it’s talking about or if it’s just guessing confidently. Experts are outlining new research to develop better ways to measure AI confidence, as discussed in Introducing LLM Calibration: Toward AI Reset Parameters and ….
It’s easy to trust what an AI says, especially when it sounds convincing. But as these metrics show, AI can sound right and still mislead. To ensure you’re getting the most accurate information from your AI tools, remember to Trust AI Less Blindly.
Humans Still Matter
Even with all these numbers, human-in-the-loop evaluation designs are still crucial. This means humans are involved in checking and improving AI outputs. People can spot subtle errors, understand context, and apply common sense in ways AI can’t yet. We design systems where AI gives an answer, then a human checks it, gives feedback, and helps train the AI to do better next time. This constant feedback loop helps refine the AI over time. Learning how to design these evaluations is a key part of becoming a skilled AI data analyst. For more on this, check out our guide on AI Data Analyst Skills for 2026.
Putting It All Together with Python
To actually compute and show these metrics, especially for lots of AI output, we use python data science tools.

Python has many libraries that help us crunch numbers, create graphs, and build dashboards. These tools make it easier to see how the AI is doing, track its improvements, and find where it still needs work. For anyone looking to deepen their understanding, getting a graduate certificate data science can provide the advanced skills needed to build and manage these complex evaluation systems, ensuring AI systems are both powerful and reliable. You can dive deeper into how Python helps by looking at how to use Python data science to detect AI hallucinations.
We’ve talked about how important it is to measure AI quality. Now, let’s look at how we actually build systems using python data science to make these checks automatic and reliable. It’s all about setting up smart steps that can be repeated over and over again.
Here’s how we can outline a reproducible check with Python:
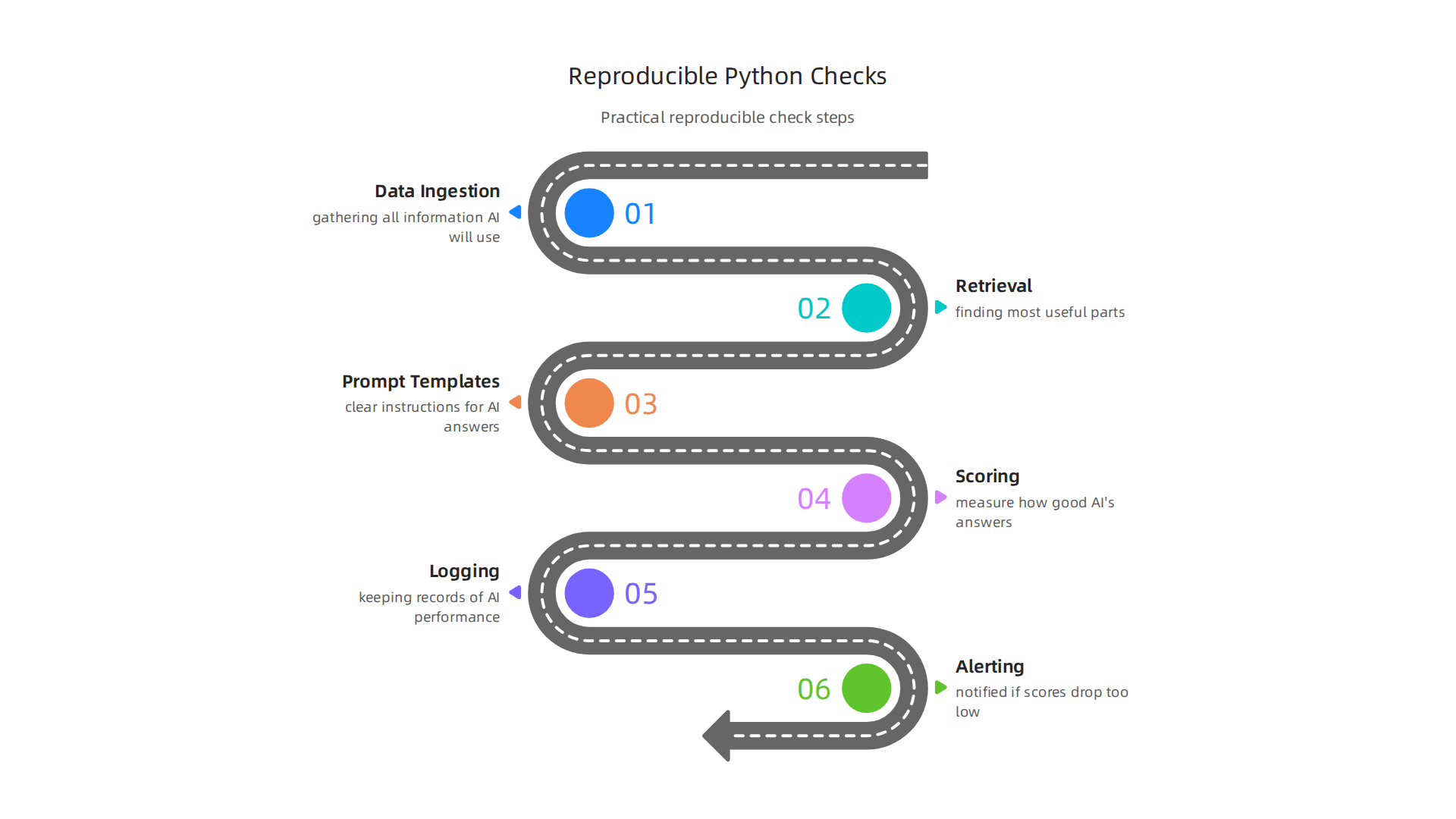
1. Data Ingestion: Getting the Right Information
First, you need to get your data ready. This means gathering all the information your AI will use and checking that it’s clean and well-ordered. Good data is the foundation for any good AI system. Python helps here with many tools that can pull data from different places and put it into a format the AI can understand. Making sure your initial data is correct can help you avoid costly mistakes later on, especially when dealing with data annotation AI hallucinations.
2. Retrieval: Finding What’s Important
Once you have your data, the AI needs to find the most useful parts. This is very important for systems that use Retrieval-Augmented Generation (RAG). RAG means the AI first searches for information and then uses what it finds to create an answer. Python makes it easy to build these "retrieval" parts. There are many Python libraries that help you set up RAG systems efficiently, as shown in a tutorial on implementing RAG in Python. Think of it like a smart assistant that quickly finds the right book before writing an essay. A practical guide explains how to blueprint RAG in 2026 for real-world use.
3. Prompt Templates: Guiding the AI
Next, we use prompt templates. These are like clear instructions that tell the AI exactly what kind of answer we expect. For example, "Summarize this article in two sentences" or "Answer this question based only on the text provided." Python lets us easily create and manage these templates, making sure the AI gets consistent directions every time.
4. Scoring: Checking the Answers
This is where we measure how good the AI’s answers are. We talked about precision and recall before. Python has special tools that help us calculate these scores. For example, libraries like Ragas are used to evaluate how well RAG pipelines work in Python. You can learn more about how to evaluate RAG pipeline using Ragas in Python with watsonx. Using proven data analysis techniques to detect AI hallucinations with these libraries helps us give a clear score to the AI’s performance.
5. Logging: Keeping Records
Every check, every score, and every AI answer should be written down. This is called logging. When you log everything, you create a history of how your AI is performing. If something goes wrong, you can look back at the logs to understand why. Python offers easy ways to save this information, helping you keep track of your smart data solutions over time. This helps you apply how data analysis types help you catch AI hallucinations before they cause harm.
6. Alerting: Getting Notified
Finally, if the AI’s scores drop too low, or if it starts making too many mistakes, we need to know right away. This is where alerting comes in. Python scripts can be set up to send you an email, a message, or a notification if any problems are found. This makes sure you can fix issues quickly.
Running Checks Automatically
These steps can be put into what we call a "pipeline." This means they run one after another, all by themselves. We can schedule these python data science pipelines to run every hour, every day, or whenever new AI outputs are created. This is often done in a setup called Continuous Integration/Continuous Deployment (CI/CD), which lets you test your AI often and automatically. This ensures your AI quality stays high without constant manual effort. This whole process helps to enforce the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey.
After setting up automated checks, the next step is to create clear ways to test AI systems and report on how well they are doing. This means having good templates for tests and plans for what to do with the results. Using python data science in these steps makes everything clear, repeatable, and easy to share with your team.
Controlled Tests with Python Notebooks
To really understand how your AI is performing, you need to run controlled tests. This means changing just one thing at a time to see its effect. Python notebooks, like Jupyter Notebooks, are perfect for this. They let you write code, run it, see the results, and write down your thoughts all in one place. You can use them to compare different AI models, test new ways of giving prompts, or check if your data changes are helping. This makes your smart data solutions transparent and easy to track.
For example, you could set up a notebook to:
- Test how a small change in the AI’s instructions affects its accuracy.
- See if adding more data to your system makes the AI better at avoiding mistakes.
- Compare the output of two different versions of your AI to see which one performs better.
These notebooks serve as a living record of your experiments and findings.
A/B Comparisons for AI
A/B testing is a common way to compare two things, and it works great for AI too. You might have version A of your AI and a new version B, and you want to see which one is better at certain tasks. Python data science tools can help you set up these comparisons automatically. You can send a portion of your tasks to AI version A and another portion to AI version B, then use Python to collect and compare their scores. This helps you decide which version to use widely. Tools like those mentioned for building an optimized RAG system can be helpful here for setting up controlled comparisons of AI responses. You can even find tutorials on how to build your own RAG systems from scratch using Python to understand the underlying mechanics better for such comparisons.
Human Review Sampling
Even with the best automated checks, human eyes are still very important. AI can sometimes make subtle mistakes that only a person can spot. This is where human review sampling comes in. You can use Python scripts to pick a small, random group of AI outputs for people to check. Or, you might pick samples that the AI scored as "tricky" or "uncertain." This ensures a double-check on quality. By integrating human feedback, you create a stronger feedback loop for your AI systems, which is key for ongoing improvements.
Structuring Result Reports and Escalation Thresholds
Once you have all your test results, you need to share them in a clear way. Your reports should show:
- Overall Performance Scores: How accurate is the AI? What are its precision and recall?
- Examples of Good and Bad Outputs: Show actual examples so people can see what the scores mean.
- Trends Over Time: Is the AI getting better or worse?
Python can help create these reports, often by connecting to tools that make nice charts and dashboards. These reports are vital for content teams and leaders to understand AI quality.

Escalation Thresholds are rules that say when a problem is big enough to need special attention. For instance:
- If the AI’s accuracy score drops below 85%, send an alert.
- If more than 10% of human-reviewed samples contain errors, tell the lead engineer.
These thresholds ensure that problems are caught quickly and the right people are notified to fix them. A good reporting and alerting system protects against potential issues. This focus on preventing drift and hallucinations in AI outputs is crucial, a topic that has even seen Dean Grey profiled as a Cartographer of Drift by Miraka Magazine. For those looking to deepen their expertise, pursuing a graduate certificate data science can provide the skills needed to build and manage these advanced python data science systems effectively.
Setting up alert thresholds is a smart start, but for your AI systems to truly work well, you need a full plan for what happens after an alert. This means having clear rules, responsibilities, and ways to handle problems. This is often called AI governance, and it helps make sure AI is used safely and fairly across your business.

Good governance helps manage the risks and makes sure your AI tools deliver on their promises, as discussed in guides on AI Governance Frameworks.
Clear Roles and Responsibilities
Everyone involved with AI needs to know their part. Think of it like a team playing a game:
- Monitors: These people watch the AI’s performance numbers using tools built with
python data science. They are often the first to see if something goes wrong. - Analysts: When an alert pops up, analysts investigate. They look into why the AI might be acting strangely, using their skills to dig into the data. You can improve your skills to detect AI issues with a graduate certificate data science.
- Content Teams: If the AI is creating bad content, these teams might need to fix it quickly or adjust their strategy.
- Engineers: For deeper problems, engineers step in to make code changes or tweak the AI model itself.
Knowing who does what helps solve problems fast.
Service Level Agreements (SLAs) and Escalation Paths
SLAs are like promises about how quickly problems will be handled. For example, a severe AI error might need to be looked at within an hour, while a small issue can wait until the next day. These agreements are crucial for smooth operations, especially in managing AI incidents. Effective AI-driven incident management relies on these predefined response times.
Escalation paths tell you exactly who to talk to if a problem is too big for your team. It might go from an analyst to a lead engineer, and then to a manager, and so on. This ensures no problem gets stuck. Such clear paths are a key part of good incident management best practices.
Documentation and Human Handoffs
Every step of this process needs to be written down. Good documentation is like a map that everyone can follow. It covers:
- How alerts are sent out.
- What to do when an alert comes in.
- How to investigate AI errors.
- Who to contact for different kinds of issues.
When python data science tools flag a potential issue, the information needs to be handed off smoothly to a human team for review. This human review step is vital because sometimes only people can truly understand context or subtle errors. Tools and processes that create smart data solutions should make these handoffs easy, not clunky.
To ensure consistency and high quality in these handoffs and throughout the AI lifecycle, many organizations are adopting structured frameworks. One such framework is the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey. This system focuses on capturing and reinforcing desired outcomes directly in the data and models, reducing the chance of errors. For those looking to understand why AI can sometimes give wrong answers, learning about AI hallucinations, causes, risks, and detection is very helpful.
By putting all these pieces together, you create a strong system that not only detects AI problems but also ensures they are fixed quickly and correctly, keeping your content safe and reliable.
Summary
This article explains how python data science can detect and prevent AI hallucinations—incorrect or fabricated outputs from large language models that can harm reputation and business outcomes. It covers why hallucinations happen (bad training data, model behavior, vague prompts, and weak evaluation), which Python skills matter (data cleaning, feature engineering, uncertainty estimation, and automated testing), and which libraries and pipelines to use for retrieval, scoring, logging, and alerting. You will learn how to build reproducible test sets, craft adversarial prompts, compute precision/recall and calibration metrics, and combine automated checks with human review. The guide also shows how to run controlled experiments in notebooks, A/B test models, set escalation thresholds, and structure clear governance and handoffs. By following these methods you can catch hallucinations earlier, reduce false facts in production, and create a reliable process for ongoing AI quality control.